
Java数据结构与算法
线性结构和 非线性结构

稀疏数组SparseArray
需求
记录棋盘的位置 可用用二位数组将它保存 ,但是会发现记录很多没有意义的数据很多空间浪费 可以用稀疏数组进行优化

介绍
稀疏数组就是压缩缩多余的冗余数据

第一行的记录原表的行列数和 非0值的个数

实例


代码实现
package com.cbx.sparsearray;
/**
* @author cbx
* @date 2021/11/30
* @apiNote
*/
public class SparseArray {
public static void main(String[] args) {
// 创建一个原始的二维数组11*11
// 0:表示没有棋子,1表示 黑子 2表示 蓝子
int chessArr1[][] = new int[11][11];
chessArr1[1][2] = 1;
chessArr1[2][3] = 2;
// 输出原始的二维数组
System.out.println("原始的二维数组~~");
for (int[] row : chessArr1) {
for (int data : row) {
System.out.printf("%d\t",data);
}
System.out.println();
}
// 将二维数组 转 稀疏数组的思路
// 1. 先遍历二维数组 得到非0数据的个数
int sum = 0;
for (int i = 0; i < 11; i++) {
for (int j = 0; j < 11; j++) {
if (chessArr1[i][j] != 0){
sum++;
}
}
}
// 2. 创建对应的稀疏数组
int sparseArr[][] = new int[sum+1][3];
// 给稀疏数组赋值
sparseArr[0][0] = 11;
sparseArr[0][1] = 11;
sparseArr[0][2] = sum;
// 遍历二维数组,将非0的值存到sparseArr中
int count = 0; // count 用于记录是第几个非0数据
for (int i = 0; i < 11; i++) {
for (int j = 0; j < 11; j++) {
if (chessArr1[i][j] != 0){
count++;
sparseArr[count][0] = i;
sparseArr[count][1] = j;
sparseArr[count][2] = chessArr1[i][j];
}
}
}
// 输出稀疏数组的形式
System.out.println();
System.out.println("得到的稀疏数组~~");
for (int i = 0; i < sparseArr.length; i++) {
System.out.printf("%d\t%d\t%d\t\n",sparseArr[i][0],sparseArr[i][1],sparseArr[i][2]);
}
System.out.println();
// 稀疏数组恢复成二维数组
// 1 读取稀疏数组的第一行 根据第一行的数据, 创建原始的二维数组
int chessArr2[][] = new int[sparseArr[0][0]][sparseArr[0][1]];
// 2 在读取稀疏数组的后几行 并赋值(从第二行开始)
for (int i = 1; i < sparseArr.length; i++) {
chessArr2[sparseArr[i][0]][sparseArr[i][1]] = sparseArr[i][2];
}
// 输出恢复后的二维数组
System.out.println();
System.out.println("恢复后的二维数组");
for (int[] row : chessArr2) {
for (int data : row) {
System.out.printf("%d\t",data);
}
System.out.println();
}
}
}
代码执行结果
输出原始的二维数组
0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 0 0 0 0 0
0 0 0 2 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
非0数据的个数 sum=2
得到的稀疏数组为:
11 11 2
1 2 1
2 3 2
输出恢复的二维数组
0 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 0 0 0 0 0
0 0 0 2 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
队列
介绍

上图的清晰图 rear待表队列的尾部 front代表数据的头部 存入数据时 front不变 rear变化 存数据时 rear位置不变 front 的位置在变化

数组模拟队列思路
rear == maxSize-1 为满 front指向队列头部的头一个位置 rear指向队列尾部的具体位置

代码实现
package com.cbx.queue;
import java.util.Scanner;
/**
* @author cbx
* @date 2021/12/1
* @apiNote
*/
public class ArrayQueueDemo {
public static void main(String[] args) {
// 测试
// 创建一个队列
ArrayQueue arrayQueue = new ArrayQueue(3);
char key = ' ';// 接受用户输入
Scanner scanner = new Scanner(System.in);
boolean loop = true; // 控制循环
// 输出一个菜单
while (loop) {
System.out.println("s(show): 显示队列");
System.out.println("e(exit): 退出程序");
System.out.println("a(add): 添加数据到队列");
System.out.println("g(get): 从队列取出数据");
System.out.println("h(head): 查看队列头的数据");
key = scanner.next().charAt(0); // 接收这个字符
switch (key){
case 's':
arrayQueue.showQueue();
break;
case 'a':
System.out.println("输入一个数");
int value = scanner.nextInt();
arrayQueue.addQueue(value);
break;
case 'g':
try{
System.out.println("取出的数据:"+arrayQueue.getQueue());
}catch (Exception e){
System.out.println(e.getMessage());
}
break;
case 'h':
try {
System.out.println("队列头部的数据:"+arrayQueue.headQueue());
}catch (Exception e){
System.out.println(e.getMessage());
}
break;
case 'e':
scanner.close();
loop = false;
break;
default:
break;
}
}
System.out.println("程序退出");
}
}
// 使用数组模拟队列-编写一个ArrayQueue类
class ArrayQueue{
private int maxSize; // 表示数组最大容量
private int front; // 队列头
private int rear; // 队列尾
private int[] arr; // 该数组用于存放数据,模拟队列
// 创建队列的构造器
public ArrayQueue(int arrMaxSize){
maxSize = arrMaxSize;
arr = new int[maxSize];
front = -1; // 指向队列头部,分析出front是指向队列头的前一个位置
rear = -1; // 指向队列尾,指向队列尾的数据(即就是队列的最后一个数据)
}
// 判断队列是否满了
public boolean isFull(){
return rear == maxSize - 1;
}
// 判断队列是否为空
public boolean isEmpty(){
return rear == front;
}
// 添加数据到队列
public void addQueue(int n){
// 判断队列是否
if (isFull()){
System.out.println("队列满,不能加入数据~");
return;
}
rear++; // 让rear 后移
arr[rear] = n;
}
// 获取队列的数据,出队列
public int getQueue(){
// 判断队列是否为空
if (isEmpty()){
// 通过抛出异常
throw new RuntimeException("队列空,不能取数据");
}
front++;
return arr[front];
}
// 显示队列的所有数据
public void showQueue(){
// 遍历
if (isEmpty()){
System.out.println("队列空的,没有数据~~");
return;
}
for (int i = 0; i < arr.length; i++) {
System.out.printf("arr[%d]=%d\n",i,arr[i]);
}
}
// 显示队列的头数据,注意不是取数据
public int headQueue(){
// 判断队列是否为空
if (isEmpty()){
// 通过抛出异常
throw new RuntimeException("队列空,不能取数据");
}
return arr[front+1];
}
}
控制台结果
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
队列为空
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
arr[0]=10
arr[1]=0
arr[2]=0
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
20
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
arr[0]=10
arr[1]=20
arr[2]=30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
40
队列满,不能加入数据
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
h
队列头部的数据:10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
h
队列头部的数据:20
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:20
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
队列为空不能取数据
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
h
队列为空,没有头数据
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
问题
现在队列经历了加满 也全部取出 当前列表理论上为空 但是任然无法加入数据 这个数组无法复用 只能使用一次 没有到达复用的效果 需要将这个数组由算法改造成一个环形数组(取模)

数组模拟环形队列
注意现在调整了front 和 rear 队列的

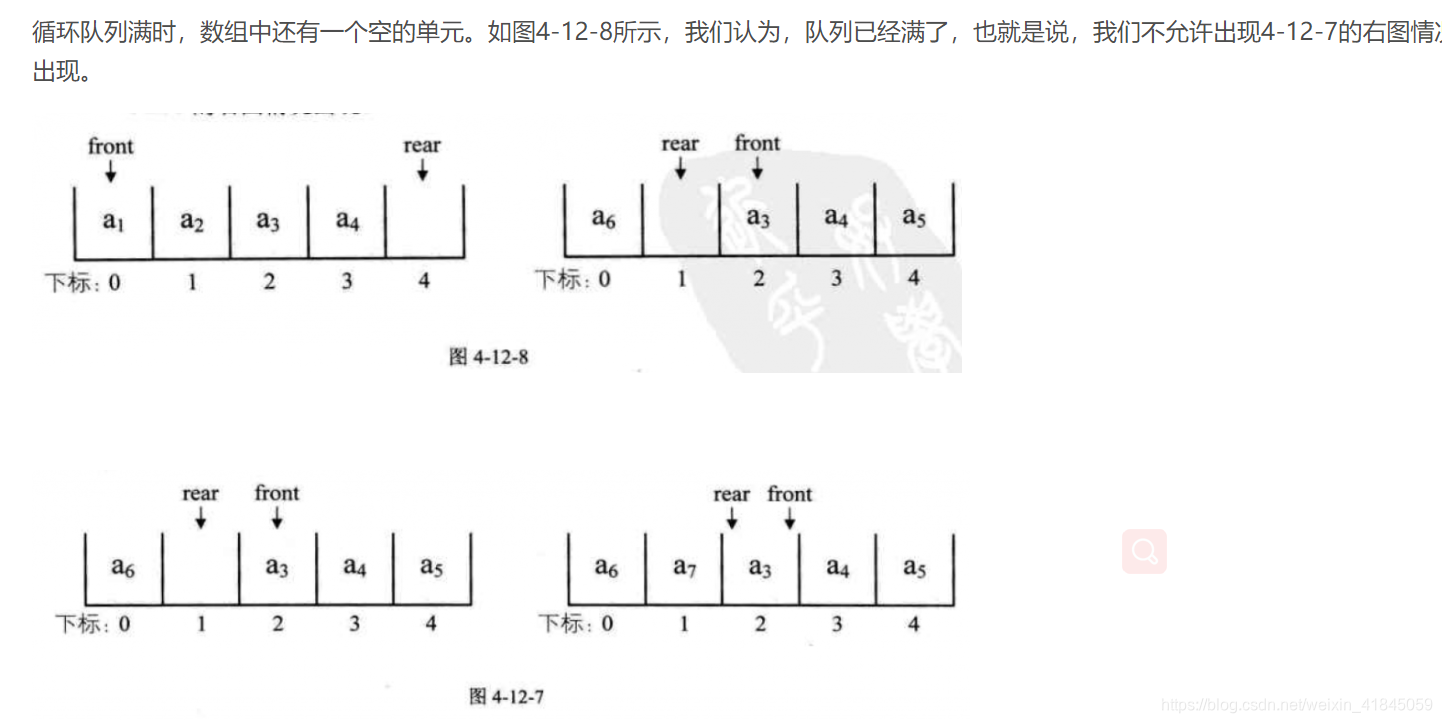
那么,循环队列为什么用空一个元素的位置呢???
这个是根据需要来用的
循环队列中,由于入队时尾指针向前追赶头指针;出队时头指针向前追赶尾指针,造成队空和队满时头尾指针均相等。因此,无法通过条件front==rear来判别队列是"空"还是"满"。
解决这个问题的方法至少有三种:
①另设一布尔变量以区别队列的空和满;
②少用一个元素的空间。约定入队前,测试尾指针在循环意义下加1后是否等于头指针,若相等则认为队满(注意:rear所指的单元始终为空);
③使用一个计数器记录队列中元素的总数(即队列长度)。
环形队列代码实现
package com.cbx.queue;
import java.util.Scanner;
/**
* @author cbx
* @date 2021/12/1
* @apiNote
*/
public class CircleArrayQueue {
public static void main(String[] args) {
// 测试
// 创建一个环形队列
CircleQueue arrayQueue = new CircleQueue(4); // 设置为4 但是数组的有效空间是3
char key = ' ';// 接受用户输入
Scanner scanner = new Scanner(System.in);
boolean loop = true; // 控制循环
// 输出一个菜单
while (loop) {
System.out.println("s(show): 显示队列");
System.out.println("e(exit): 退出程序");
System.out.println("a(add): 添加数据到队列");
System.out.println("g(get): 从队列取出数据");
System.out.println("h(head): 查看队列头的数据");
key = scanner.next().charAt(0); // 接收这个字符
switch (key){
case 's':
arrayQueue.showQueue();
break;
case 'a':
System.out.println("输入一个数");
int value = scanner.nextInt();
arrayQueue.addQueue(value);
break;
case 'g':
try{
System.out.println("取出的数据:"+arrayQueue.getQueue());
}catch (Exception e){
System.out.println(e.getMessage());
}
break;
case 'h':
try {
System.out.println("队列头部的数据:"+arrayQueue.headQueue());
}catch (Exception e){
System.out.println(e.getMessage());
}
break;
case 'e':
scanner.close();
loop = false;
break;
default:
break;
}
}
System.out.println("程序退出");
}
}
class CircleQueue {
private int maxSize; // 表示数组最大容量
// front 的变量的含义 做调整 就指向队列的第一个元素 也就是 arr[front] 是第一个头元素
// front初始值变为0
private int front; // 队列头
// rear 变量的含义做一个调整 rear指向队列的最后元素的后一个位置 因为希望空出一个空间做约定 rear的初始值为0
private int rear; // 队列尾
private int[] arr; // 该数组用于存放数据,模拟队列
// 创建队列的构造器
public CircleQueue(int arrMaxSize) {
maxSize = arrMaxSize;
arr = new int[maxSize];
//front = rear = 0 ; // 队列头部和尾部 front指向队列头部的头一个位置 rear指向队列尾部的具体位置
}
// 判断队列是否满了
public boolean isFull() {
return (rear+1)% maxSize == front;
}
// 判断队列是否为空
public boolean isEmpty() {
return rear == front;
}
// 添加数据到队列
public void addQueue(int n) {
// 判断队列是否
if (isFull()) {
System.out.println("队列满,不能加入数据~");
return;
}
// rear指向对位的后一个位置 直接将数据加入 在后移rear指针
arr[rear] = n;
// 要考虑取模 如果rear已经在 数组的最后位置 需要进行取模到数组的开始部分
rear = (rear + 1)% maxSize;
}
// 获取队列的数据,出队列
public int getQueue() {
// 判断队列是否为空
if (isEmpty()) {
// 通过抛出异常
throw new RuntimeException("队列空,不能取数据");
}
// 这里需要分析出front是 指向队列的第一个元素
// 1 先把 front对应的值 保存到临时变量
// 2 将front 后移
// 3 将临时保存的变量返回
int value = arr[front];
front = (front + 1) % maxSize;
return value;
}
// 显示队列的所有数据
public void showQueue() {
// 遍历
if (isEmpty()) {
System.out.println("队列空的,没有数据~~");
return;
}
// 思路: 从front开始遍历, 遍历多少个元素
//
for (int i = front; i < front + size(); i++) {
System.out.println("arr["+ i % maxSize +"]="+arr[i % maxSize]);
}
}
// 显示队列的头数据,注意不是取数据
public int headQueue() {
// 判断队列是否为空
if (isEmpty()) {
// 通过抛出异常
throw new RuntimeException("队列空,不能取数据");
}
return arr[front];
}
// 求出当前队列的有效数据的个数
public int size() {
return (rear + maxSize - front) % maxSize;
}
}
运行结果
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
队列为空
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a 20
输入一个数
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
arr[0]=10
arr[1]=20
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
arr[0]=10
arr[1]=20
arr[2]=30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
输入一个数
40
队列满,不能加入数据
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
arr[1]=20
arr[2]=30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a 10
输入一个数
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
s
arr[1]=20
arr[2]=30
arr[3]=10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a 70
输入一个数
队列满,不能加入数据
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
h
队列头部的数据:20
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:20
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:30
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
取出的数据:10
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
g
队列为空不能取数据
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a 50
输入一个数
s(show): 显示对列
e(exit): 退出程序
a(add): 添加数据到对列
g(get): 从对列取出数据
h(head): 查看对列头的数据
a
链表

小结上图:
链表是以节点的方式来存储, 是链式存储
每个节点包含 data 域, next 域:指向下一个节点.
如图:发现 链表的各个节点不一定是连续存储.
链表分 带头节点的链表和 没有头节点的链表,根据实际的需求来确定
单链表
单链表看似连续 但是并不是 这只是逻辑结构

不考虑排名

代码:
package com.cbx.linkedlist;
/**
* @author cbx
* @date 2021/12/2
* @apiNote
*/
public class SingleLinkedLIstDemo {
public static void main(String[] args) {
// 进行测试
// 先创建节点
HeroNode hero1 = new HeroNode(1,"卡特","不详之刃");
HeroNode hero2 = new HeroNode(2,"亚索","疾风剑豪");
HeroNode hero3 = new HeroNode(3,"劫","影流之主");
HeroNode hero4 = new HeroNode(4,"乐芙兰","诡术妖姬");
// 创建链表
SingleLinkedList singleLinkedList = new SingleLinkedList();
// 加入
singleLinkedList.add(hero1);
singleLinkedList.add(hero3);
singleLinkedList.add(hero2);
singleLinkedList.add(hero4);
// 显示
singleLinkedList.list();
}
}
// 定义SingleLinkedList 管理我们的英雄
class SingleLinkedList{
// 先初始化一个头节点,头节点不要动,不要存放具体的数据
private HeroNode head = new HeroNode(0,"","");
// 添加节点到单向链表
// 思路,当不考虑编号顺序时
// 1. 找到当前链表的最后节点
// 2. 将最后这个节点的next 指向 新的节点
public void add(HeroNode heroNode){
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode temp = head;
// 遍历链表,找到最后
while (true){
// 找到链表的最后
if (temp.next == null){
break;
}
// 如果没有找到最后,将temp后移
temp = temp.next;
}
// 当退出while循环时,temp就指向了链表的最后
// 将最后这个节点的next 指向 新的节点
temp.next = heroNode;
}
// 显示链表[遍历]
public void list(){
// 判断链表是否为空
if (head.next == null){
System.out.println("链表为空");
return;
}
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode temp = head.next;
while (true){
// 判断是否到链表最后
if (temp == null){
break;
}
// 输出节点的信息
System.out.println(temp);
// 将temp后移,一定小心
temp = temp.next;
}
}
}
// 定义HeroNode,每个HeroNode对象就是一个节点
class HeroNode{
public int no;
public String name;
public String nickname;
public HeroNode next; // 指向下一个节点
// 构造器
public HeroNode(int no, String name, String nickname) {
this.no = no;
this.name = name;
this.nickname = nickname;
}
@Override
public String toString() {
return "HeroNode{" +
"no=" + no +
", name='" + name + '\'' +
", nickname='" + nickname +"}";
}
}
考虑排名

修改
思路(1) 先找到该节点,通过遍历,(2) temp.name = newHeroNode.name ; temp.nickname= newHeroNode.nickname
删除

代码:
package com.cbx.linkedlist;
/**
* @author cbx
* @date 2021/12/2
* @apiNote
*/
public class SingleLinkedLIstDemo {
public static void main(String[] args) {
// 进行测试
// 先创建节点
HeroNode hero1 = new HeroNode(1,"卡特","不详之刃");
HeroNode hero2 = new HeroNode(2,"亚索","疾风剑豪");
HeroNode hero3 = new HeroNode(3,"劫","影流之主");
HeroNode hero4 = new HeroNode(4,"乐芙兰","诡术妖姬");
// 创建链表
SingleLinkedList singleLinkedList = new SingleLinkedList();
// 加入
// singleLinkedList.add(hero1);
// singleLinkedList.add(hero3);
// singleLinkedList.add(hero2);
// singleLinkedList.add(hero4);
singleLinkedList.addByOrder(hero1);
singleLinkedList.addByOrder(hero3);
singleLinkedList.addByOrder(hero2);
singleLinkedList.addByOrder(hero4);
// singleLinkedList.addByOrder(hero4);
// 显示
singleLinkedList.list();
// 测试修改节点的代码
HeroNode newHeroNode = new HeroNode(2,"风男","疾风剑豪~~");
singleLinkedList.update(newHeroNode);
System.out.println("修改后的链表情况~~");
singleLinkedList.list();
// 删除一个节点
singleLinkedList.del(1);
singleLinkedList.del(4);
singleLinkedList.del(2);
singleLinkedList.del(3);
System.out.println("删除后的链表情况~~");
singleLinkedList.list();
}
}
// 定义SingleLinkedList 管理我们的英雄
class SingleLinkedList{
// 先初始化一个头节点,头节点不要动,不要存放具体的数据
private HeroNode head = new HeroNode(0,"","");
// 添加节点到单向链表
// 思路,当不考虑编号顺序时
// 1. 找到当前链表的最后节点
// 2. 将最后这个节点的next 指向 新的节点
public void add(HeroNode heroNode){
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode temp = head;
// 遍历链表,找到最后
while (true){
// 找到链表的最后
if (temp.next == null){
break;
}
// 如果没有找到最后,将temp后移
temp = temp.next;
}
// 当退出while循环时,temp就指向了链表的最后
// 将最后这个节点的next 指向 新的节点
temp.next = heroNode;
}
// 第二种方式在添加英雄时,根据排名将英雄插入到指定的位置
// (如果有这个排名,则添加失败,并给出提示)
public void addByOrder(HeroNode heroNode){
// 因为head节点不能动,因此我们需要一个辅助遍历temp
// 因为单链表,因此我们找的temp是位于添加位置的前一个节点,否则插入不了
HeroNode temp = head;
boolean flag = false; // flag标志添加的编号是否存在,默认为false
while (true){
if (temp.next == null){ // 说明temp已经在链表的最后
break;
}
if (temp.next.no > heroNode.no){ // 位置找到,就在temp的后面插入
break;
}else if (temp.next.no == heroNode.no){ // 说明希望添加的heroNode的编号已然存在
flag = true; // 说明编号存在
break;
}
temp = temp.next; // 后移,遍历当前链表
}
// 判断flag的值
if (flag){
System.out.printf("准备插入的英雄的编号%d已经存在了,不能加入\n",heroNode.no);
}else {
// 插入到链表中,temp的后面
heroNode.next = temp.next;
temp.next = heroNode;
}
}
// 修改节点的信息,根据no编号来修改,即no编号不能改
// 说明
// 1. 根据newHeroNode 的 no来修改即可
public void update(HeroNode newHeroNode){
// 判断是否空
if (head.next == null){
System.out.println("链表为空");
return;
}
// 找到需要修改的节点,根据no编号
// 定义一个辅助变量
HeroNode temp = head.next;
boolean flag = false; // 表示是否找到节点
while (true){
if (temp == null){
break; // 已经遍历完链表
}
if (temp.no == newHeroNode.no){
// 找到
flag = true;
break;
}
temp = temp.next;
}
// 根据flag 判断是否找到要修改的节点
if (flag){
temp.name = newHeroNode.name;
temp.nickname = newHeroNode.nickname;
}else { // 没有找到
System.out.printf("没有找到编号%d的节点,不能修改\n",newHeroNode.no);
}
}
// 思路
// 1. head不能动,因此我们需要一个temp辅助节点找到待删除节点的前一个节点
// 2. 说明我们在比较时,是temp.next.no 和 需要删除的节点的no比较
public void del(int no){
HeroNode temp = head;
boolean flag = false; // 标志是否找到待删除的节点
while(true){
if (temp.next == null){
break;
}
if (temp.next.no == no){
// 找到了待删除节点的前一个节点temp
flag = true;
break;
}
temp = temp.next;
}
// 判断flag
if (flag) { // 找到
// 可以删除
temp.next = temp.next.next;
}else {
System.out.printf("要删除的%d节点不存在\n",no);
}
}
// 显示链表[遍历]
public void list(){
// 判断链表是否为空
if (head.next == null){
System.out.println("链表为空");
return;
}
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode temp = head.next;
while (true){
// 判断是否到链表最后
if (temp == null){
break;
}
// 输出节点的信息
System.out.println(temp);
// 将temp后移,一定小心
temp = temp.next;
}
}
}
// 定义HeroNode,每个HeroNode对象就是一个节点
class HeroNode{
public int no;
public String name;
public String nickname;
public HeroNode next; // 指向下一个节点
// 构造器
public HeroNode(int no, String name, String nickname) {
this.no = no;
this.name = name;
this.nickname = nickname;
}
@Override
public String toString() {
return "HeroNode{" +
"no=" + no +
", name='" + name + '\'' +
", nickname='" + nickname +"}";
}
}
单链表面试题

求单链表的有效节点的个数
// 方法: 获取到单链表的节点的个数(如果是带头结点的链表,需求不统计头节点)
/**
*
* @param head 链表的头节点
* @return 返回的就是有效节点的个数
*/
public static int getLength(HeroNode head){
if (head.next == null){ //空链表
return 0;
}
int length = 0;
// 定义一个辅助的常量,这里我们没有统计头节点
HeroNode cur = head.next;
while (cur != null){
length++;
cur = cur.next; // 遍历
}
return length;
}
求单链表的倒数第K个节点
// 查找单链表中的倒数第k个节点[新浪面试题]
// 思路
// 1. 编写一个方法,接收head节点,同时接受一个index
// 2. index表示是倒数第index个节点
// 3. 先把链表从头到尾遍历,得到的链表总长度getLength
// 4. 得到size后,我们从链表的第一个开始遍历(size-index)个,就可以得到
// 5. 如果找到了,则返回该节点,否则返回null
public static HeroNode findLastIndexNode(HeroNode head,int index){
// 判断如果链表为空,返回null
if (head.next == null){
return null;
}
// 第一个遍历得到链表的长度(节点个数)
int size = getLength(head);
// 第二次遍历size-index位置,就是我们倒数的第K个节点
// 先做一个index的校验
if (index <= 0||index > size){
return null;
}
// 定义给辅助变量,for循环定位到倒数的index
HeroNode cur =head.next;//3 //3-1=2
for (int i = 0; i < size - index; i++) {
cur = cur.next;
}
return cur;
}
单链表的反转 (有点难度)

// 将单链表反转
public static void reverseList(HeroNode head){
// 如果当前链表为空,或者只有一个节点,无需反转,直接返回
if (head.next==null || head.next.next==null){
return;
}
// 定义一个辅助的指针(变量),帮助我们遍历原来的链表
HeroNode cur = head.next;
HeroNode next = null; // 指向当前节点[cur]的下一个节点
HeroNode reverseHead = new HeroNode(0,"","");
// 遍历原来的链表,每遍历一个节点,就将其取出,并放在新的链表reverseHead的最前端
// 动脑筋
while (cur != null){
next = cur.next;// 先暂时保存当前节点的下一个节点,因为后面需要用到
cur.next = reverseHead.next; // 将cur的下一个节点指向新的链表的最前端
reverseHead.next = cur;// 将cur连接到新的链表上
cur = next;// 让cur后移
}
// 将head.next指向reverseHead.next,实现单链表的反转
head.next = reverseHead.next;
}
从尾到头打印单列表

// 方式2
// 可以利用栈这个数据结构,将各个节点压入到栈中,然后利用栈的先进先出的特点,就实现了逆序打印的效果
public static void reversePrint(HeroNode head){
if (head.next == null){
return;// 空链表,不能打印
}
// 创建一个栈,将各节点压入栈中
Stack<HeroNode> stack = new Stack<>();
HeroNode cur = head.next;
// 将链表的所有节点压入栈
while (cur!=null){
stack.push(cur);
cur = cur.next; // cur后移,这样就可以压入下一个节点
}
// 将栈中的节点进行打印,pop出栈
while (stack.size()>0){
System.out.println(stack.pop());
}
}
合并两个有序链表,合并后依然有序(递归)
public static HeroNode mergeTwoLists(HeroNode l1, HeroNode l2) {
if (l1 == null) return l2;
if (l2 == null) return l1;
HeroNode head = null;
if (l1.no <= l2.no){
head = l1;
head.next = mergeTwoLists(l1.next, l2);
} else {
head = l2;
head.next = mergeTwoLists(l1, l2.next);
}
return head;
}
双向链表
单链表的问题

package com.cbx.linkedlist;
/**
* @author cbx
* @date 2021/12/4
* @apiNote
*/
public class DoubleLinkedListDemo {
public static void main(String[] args) {
//测试
System.out.println("双向链表的测试");
// 先创建节点
HeroNode2 hero1 = new HeroNode2(1,"卡特1","不详之刃");
HeroNode2 hero2 = new HeroNode2(4,"亚索4","疾风剑豪");
HeroNode2 hero3 = new HeroNode2(5,"劫5","影流之主");
HeroNode2 hero4 = new HeroNode2(7,"乐芙兰7","诡术妖姬");
// 创建一个双向链表
DoubleLinkedList doubleLinkedList = new DoubleLinkedList();
doubleLinkedList.add(hero1);
doubleLinkedList.add(hero2);
doubleLinkedList.add(hero3);
doubleLinkedList.add(hero4);
doubleLinkedList.list();
// 修改测试
HeroNode2 newHeroNod = new HeroNode2(7,"乐芙兰77777","诡术妖姬7");
doubleLinkedList.update(newHeroNod);
System.out.println("修改后");
doubleLinkedList.list();
//删除
doubleLinkedList.del(4);
System.out.println("删除后");
doubleLinkedList.list();
}
}
// 创建一个双向链表的类
class DoubleLinkedList{
// 先初始化一个头节点,头节点不要动,不要存放具体的数据
private HeroNode2 head = new HeroNode2(0,"","");
public HeroNode2 getHead() {
return head;
}
// 遍历双向链表的方法
public void list(){
// 判断链表是否为空
if (head.next == null){
System.out.println("链表为空");
return;
}
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode2 temp = head.next;
while (true){
// 判断是否到链表最后
if (temp == null){
break;
}
// 输出节点的信息
System.out.println(temp);
// 将temp后移,一定小心
temp = temp.next;
}
}
// 添加一个节点到双向链表的最后
public void add(HeroNode2 heroNode){
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode2 temp = head;
// 遍历链表,找到最后
while (true){
// 找到链表的最后
if (temp.next == null){
break;
}
// 如果没有找到最后,将temp后移
temp = temp.next;
}
// 当退出while循环时,temp就指向了链表的最后
// 形成一个双向链表
temp.next = heroNode;
heroNode.pre = temp;
}
// 修改一个节点的内容,可以看到双向链表的节点内容修改和单向链表一样
// 只是 节点类型改成HeroNode2
public void update(HeroNode2 newHeroNode){
// 判断是否空
if (head.next == null){
System.out.println("链表为空");
return;
}
// 找到需要修改的节点,根据no编号
// 定义一个辅助变量
HeroNode2 temp = head.next;
boolean flag = false; // 表示是否找到节点
while (true){
if (temp == null){
break; // 已经遍历完链表
}
if (temp.no == newHeroNode.no){
// 找到
flag = true;
break;
}
temp = temp.next;
}
// 根据flag 判断是否找到要修改的节点
if (flag){
temp.name = newHeroNode.name;
temp.nickname = newHeroNode.nickname;
}else { // 没有找到
System.out.printf("没有找到编号%d的节点,不能修改\n",newHeroNode.no);
}
}
// 从双向链表中删除一个节点
// 说明
// 1. 对于双向链表,我们可以直接找到要删除的这个节点
// 2. 找到后,自我删除即可
public void del(int no){
// 判断当前链表是否为空
if (head.next == null){
System.out.println("链表为空,无法删除");
return;
}
HeroNode2 temp = head.next; // 辅助变量(指针)
boolean flag = false; // 标志是否找到待删除的节点
while(true){
if (temp == null){ // 已经到链表的最后节点的next
break;
}
if (temp.no == no){
// 找到了待删除节点的前一个节点temp
flag = true;
break;
}
temp = temp.next;
}
// 判断flag
if (flag) { // 找到
// 可以删除
// temp.next = temp.next.next;[单项链表处理方式]
temp.pre.next=temp.next;
// 如果是最后一个节点,就不需要执行下面这句话,否则出现空指针
if (temp.next != null){
temp.next.pre=temp.pre;
}
}else {
System.out.printf("要删除的%d节点不存在\n",no);
}
}
}
// 定义HeroNode2,每个HeroNode对象就是一个节点
class HeroNode2{
public int no;
public String name;
public String nickname;
public HeroNode2 next; // 指向下一个节点,默认为null
public HeroNode2 pre;// 指向前一个节点,默认为null
// 构造器
public HeroNode2(int no, String name, String nickname) {
this.no = no;
this.name = name;
this.nickname = nickname;
}
@Override
public String toString() {
return "HeroNode{" +
"no=" + no +
", name='" + name + '\'' +
", nickname='" + nickname +"}";
}
}
双向链表的第二种添加方式,按照编号顺序添加
// 第二种方式在添加英雄时,根据排名将英雄插入到指定的位置
// (如果有这个排名,则添加失败,并给出提示)
public void addByOrder(HeroNode2 heroNode2){
// 因为head节点不能动,因此我们需要一个辅助遍历temp
HeroNode2 temp = head;
boolean flag = false; // flag标志添加的编号是否存在,默认为false
while (true){
if (temp.next == null){ // 说明temp已经在链表的最后
break;
}
if (temp.next.no > heroNode2.no){ // 位置找到,就在temp的后面插入
break;
}else if (temp.next.no == heroNode2.no){ // 说明希望添加的heroNode的编号已然存在
flag = true; // 说明编号存在
break;
}
temp = temp.next; // 后移,遍历当前链表
}
// 判断flag的值
if (flag){
System.out.printf("准备插入的英雄的编号%d已经存在了,不能加入\n",heroNode2.no);
}else {
// 插入到链表中,temp的后面
if (temp.next == null){ // 说明temp已经在链表的最后
temp.next=heroNode2;
heroNode2.pre = temp;
}else {
heroNode2.next = temp.next;
temp.next.pre = heroNode2;
temp.next = heroNode2;
heroNode2.pre = temp;
}
}
}
单项环形链表
约瑟夫问题

单向环形链表介绍


思路分析

package com.cbx.linkedlist;
/**
* @author cbx
* @date 2021/12/5
* @apiNote
*/
public class Josepfu {
public static void main(String[] args) {
// 测试构建和遍历
CircleSingleLinkedList circleSingleLinkedList = new CircleSingleLinkedList();
circleSingleLinkedList.addBoy(5);
circleSingleLinkedList.showBoy();
// 测试小孩出圈是否正确
circleSingleLinkedList.countBoy(1,2,5);
}
}
// 创建一个环形的单向链表
class CircleSingleLinkedList{
// 创建一个first节点(指向第一个节点的指针),当前没有编号
private Boy first = null;
// 添加小孩节点,构建成一个环形的链表
public void addBoy(int nums){
// nums做一个数据校验
if (nums<1){
System.out.println("nums的值不正确");
return;
}
Boy curBoy = null; // 辅助指针,帮助构建环形链表
// 使用for来创建我们的环形链表
for (int i = 1; i <= nums; i++) {
// 根据编号,创建小孩节点
Boy boy = new Boy(i);
// 如果是第一个小孩
if (i == 1){
first = boy;
first.setNext(first); // 构成环
curBoy = first; // 让curBoy指向第一个小孩
} else {
curBoy.setNext(boy);
boy.setNext(first);
curBoy = boy;
}
}
}
// 遍历当前的环形链表
public void showBoy(){
// 判断链表是否为空
if (first == null){
System.out.println("没有任何小孩~~");
return;
}
// 因为first不能动,因此我们仍然使用一个辅助指针完成遍历
Boy curBoy = first;
while (true){
System.out.printf("小孩的编号 %d \n",curBoy.getNo());
if (curBoy.getNext() == first){ // 说明已经遍历完毕
break;
}
curBoy = curBoy.getNext(); // 让curBoy后移
}
}
// 根据用户的输入,计算出小孩出圈的顺序
/**
*
* @param startNo 表示从第几个小孩开始报数
* @param countNum 表示数几下
* @param nums 表示最初有多少个小孩在圈中
*/
public void countBoy(int startNo,int countNum,int nums){
// 先对数据进行校验
if (first == null || startNo < 1 || startNo > nums){
System.out.println("链表为空或者参数输入有误,请重新输入");
return;
}
// 创建一个辅助指针,帮助完成小孩出圈,先让这个辅助指针指向环形链表的最后一个节点
Boy helper = first;
// 需求创建一个辅助指针(变量)helper,事先应该指向环形链表的最后一个节点
while (true){
if (helper.getNext() == first){ // 说明helper已经指向最后一个小孩节点
break;
}
helper = helper.getNext();
}
// 小孩报数前,先让 first 和 helper 移动到指定的位置,即第一个开始报数的小孩节点位置
// 让first和helper移动k-1次
for (int j = 0; j < startNo - 1; j++) {
first = first.getNext();
helper = helper.getNext();
}
// 当小孩报数时,让first和helper指针同时的移动m-1次(因为报数的第一个节点本身也要报数),然后出圈
// 这里是一个循环操作,知道圈中只有一个节点
while (true){
if (helper == first){ // 说明圈中只有一个节点
break;
}
// 让first和helper指针同时的移动countNum-1次
for (int j = 0; j < countNum-1; j++) {
first = first.getNext();
helper = helper.getNext();
}
// 这时first指向的节点,就是要出圈的小孩节点
System.out.printf("小孩%d出圈\n",first.getNo());
// 这时将first指向的小孩节点出圈
first = first.getNext();
helper.setNext(first);
}
System.out.printf("最后留在圈中的小孩编号 %d \n",helper.getNo());
}
}
// 创建一个Boy类,表示一个节点
class Boy{
private int no;// 编号
private Boy next;// 指向下一个节点,默认为null
public Boy(int no){
this.no = no;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public Boy getNext() {
return next;
}
public void setNext(Boy next) {
this.next = next;
}
}
栈

介绍


数组模拟栈

代码实现
package com.cbx.stack;
import java.util.Scanner;
/**
* @author cbx
* @date 2021/12/6
* @apiNote
*/
public class ArrayStackDemo {
public static void main(String[] args) {
// 测试一下ArrayStack是否正确
// 先创建一下ArrayStack对象->表示栈
ArrayStack stack = new ArrayStack(4);
String key = "";
boolean loop = true;// 控制是否退出菜单
Scanner scanner = new Scanner(System.in);
while (loop){
System.out.println("show: 表示显示栈");
System.out.println("exit: 退出程序");
System.out.println("push: 表示添加数据到栈中(入栈)");
System.out.println("pop: 表示从栈中取出数据(出栈)");
System.out.println("请输入你的选择");
key = scanner.next();
switch (key){
case "show":
stack.list();
break;
case "push":
System.out.println("请输入一个数");
int value = scanner.nextInt();
stack.push(value);
break;
case "pop":
try {
int res = stack.pop();
System.out.printf("出栈的数据是 %d\n",res);
} catch (Exception e) {
System.out.println(e.getMessage());
}
break;
case "exit":
scanner.close();
loop = false;
break;
default:
break;
}
}
System.out.println("程序退出~~");
}
}
// 定义一个ArrayStack 表示栈
class ArrayStack{
private int maxSize;// 栈的大小
private int[] stack;// 数组,数组模拟栈,数据就放在该数组中
private int top = -1;// top表示栈顶,初始化为-1
// 构造器
public ArrayStack(int maxSize){
this.maxSize = maxSize;
stack = new int[this.maxSize];
}
// 栈满
public boolean isFull(){
return top == maxSize - 1;
}
// 栈空
public boolean isEmpty(){
return top == -1;
}
// 入栈 --push
public void push(int value){
// 先判断栈是否满
if (isFull()){
System.out.println("栈满");
return;
}
top++;
stack[top] = value;
}
// 出栈 -pop,将栈顶的数据返回
public int pop(){
// 先判断是否为空
if (isEmpty()){
// 抛出异常
throw new RuntimeException("栈空,没有数据");
}
int value = stack[top];
top--;
return value;
}
// 显示栈的情况[遍历栈],遍历时,需要从栈顶开始显示数据
public void list(){
if (isEmpty()){
System.out.println("栈空,没有数据");
return;
}
// 需要从栈顶开始显示数据
for (int i = top; i >= 0 ; i--) {
System.out.printf("stack[%d]=%d\n",i,stack[i]);
}
}
}
链表模拟栈
代码实现
package com.cbx.stack;
/**
* @author cbx
* @date 2021/12/6
* @apiNote
*/
public class LinkedListStackDemo {
public static void main(String[] args) {
LLStack llStack=new LLStack();
llStack.push(10);
llStack.push(20);
llStack.push(30);
llStack.push(40);
llStack.push(50);
System.out.println("栈里面值的个数为:"+llStack.getLength());
llStack.pop();
System.out.println("pop一个之后,栈里面的个数 为 :"+llStack.getLength());
System.out.println("pop一个之后,栈顶的值为:"+llStack.top());
llStack.list();
}
}
class LLStack {
private LLNode headnode= new LLNode(null);
public LLNode getHeadnode(){
return headnode;
}
public boolean isEmpty(){//判断是否为空的
return headnode==null;
}
public void push(Object data){//入栈
if(headnode.getData()==null){//判断头结点的值为空的时候
headnode.setData(data);
}
else if(headnode==null){
headnode=new LLNode(data);
}
else {
LLNode newnode=new LLNode(data);
newnode.setNext(headnode);
headnode=newnode;
}
}
public Object pop(){//出栈(返回栈顶的值,并且删除)
Object data=null;
if(isEmpty()){
System.out.println("栈为空,返回值为0");
return 0;
}
data=headnode.getData();
headnode=headnode.getNext();
return data;
}
public Object top(){//返回栈顶的值,但是不删除
Object data=null;
if(isEmpty()){
System.out.println("栈为空,返回值为0");
return 0;
}
data=headnode.getData();
return data;
}
public int getLength(){//得到栈里面值的个数
int count=0;
LLNode tempnode=headnode;
if(isEmpty()||tempnode.getData()==null)//当头结点为空,并且值也为空的时候就返回0
{
count=0;
}
else
{
while(tempnode!=null)
{
count++;
tempnode=tempnode.getNext();
}
}
return count;
}
public void list(){//得到栈里面值的个数
LLNode tempnode=headnode;
if(isEmpty()||tempnode.getData()==null)//当头结点为空,并且值也为空的时候就返回0
{
System.out.println("栈为空");
return;
}
else
{
System.out.println("栈里面的值为");
while(tempnode!=null)
{
System.out.println(tempnode.getData());
tempnode=tempnode.getNext();
}
return;
}
}
}
class LLNode {
private Object data;//存放数据
private LLNode next;//指向下一个节点
public LLNode() {
}
public LLNode(Object data) {
this.data = data;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
public LLNode getNext() {
return next;
}
public void setNext(LLNode next) {
this.next = next;
}
@Override
public String toString() {
return "LLNode{" +
"data=" + data +
'}';
}
}
栈实现计算器
思路分析(中缀表达式)


代码实现(不考虑小括号)
package com.cbx.stack;
/**
* @author cbx
* @date 2021/12/6
* @apiNote
*/
public class Calculator {
public static void main(String[] args) {
String expression = "80+2*6-2";
// 创建两个栈,数栈,一个符号栈
ArrayStack2 numStack = new ArrayStack2(10);
ArrayStack2 operStack = new ArrayStack2(10);
// 定义需要的相关变量
int index = 0;
int num1 = 0;
int num2 = 0;
int oper = 0;
int res = 0;
char ch = ' '; // 将每次扫描到的char存入到ch
String keepNum = ""; // 用于拼接多位数的
// 开始while循环的扫描expression
while (true){
// 依次得到expression的每一个字符
ch = expression.substring(index,index+1).charAt(0);
// 判断ch是什么
if (operStack.isOper(ch)){// 如果是运算符
// 判断当前符号栈是否为空
if (!operStack.isEmpty()){
// 如果符号栈有操作符 就进行比较 如果当前的操作符的优先级小于等于栈中的操作符,就需要从数栈中pop出两个数
// 再从符号栈中pop出一个符号 ,进行运算,将得到的结果,入数栈 然后将 当前的操作符入符号栈
if (operStack.priority(ch) <= operStack.priority(operStack.peek())){
num1 = numStack.pop();
num2 = numStack.pop();
oper = operStack.pop();
res = numStack.cal(num1,num2,oper);
// 把运算结果存入数字栈中
numStack.push(res);
// 再把新的运算符压入符号栈中
operStack.push(ch);
}else {
// 当前操作符的优先级大于符号栈中的操作符,直接压入
operStack.push(ch);
}
}else {
// 符号栈如果为空,直接压入
operStack.push(ch);
}
}else { // 如果为数字,则直接入数栈 注意这是字符 不是真正的数字
// numStack.push(ch - 48); 这样子有问题 13 + 1 => '1' '3' '+' '1'
// 在处理多位数时, 不能发现是一个数就立即入栈 因为他可能是多位数
// 在处理数,需要向expression的表达式的index 后再看一位 , 如果是数 就进行扫描, 如果是符号才入栈
// 因此我们需要定义一个变量 keepNum字符串 ,用于拼接多位数
//numStack.push(ch-48); // ch为'1','3'这种字符char,并不是int,通过ascll码表可得真正得的数字为ch-48
//处理多为数
keepNum += ch;
// 如果ch是expression的最后一位 直接入栈
if (index == expression.length()-1){
numStack.push(ch - 48);
}else {
// 判断下一个字符 是不是数组 ,就继续扫描 ,如果是运算符 则入栈
// 只看后一位 不是index++
if (operStack.isOper(expression.substring(index + 1, index + 2).charAt(0))) {
// 如果后一位是运算符 则数字入栈
numStack.push(Integer.parseInt(keepNum));
// 重要的!!!!!! 清空keepNum
keepNum = "";
}
}
}
// 让index+1,并判断是否扫描到表达式的最后
index++; // index为索引下标,从0开始
if (index >= expression.length()){
break;
}
}
// 当表达式扫描完毕,就顺序从数栈和符号栈中弹出相应的数字和符号,并运行
while (true){
// 如果符号栈为空,则数字栈中最后只剩下一个数字,即为计算结果
if (operStack.isEmpty()){
break;
}
num1 = numStack.pop();
num2 = numStack.pop();
oper = operStack.pop();
res = numStack.cal(num1,num2,oper);
numStack.push(res);
}
// 将数栈中的最后一个数字即计算结果弹出
int res2 = numStack.pop();
System.out.printf("表达式 %s = %d \n",expression,res2);
}
}
// 定义一个ArrayStack 表示栈
class ArrayStack2{
private int maxSize;// 栈的大小
private int[] stack;// 数组,数组模拟栈,数据就放在该数组中
private int top = -1;// top表示栈顶,初始化为-1
// 构造器
public ArrayStack2(int maxSize){
this.maxSize = maxSize;
stack = new int[this.maxSize];
}
// 返回栈顶的值
public int peek(){
return stack[top];
}
// 栈满
public boolean isFull(){
return top == maxSize - 1;
}
// 栈空
public boolean isEmpty(){
return top == -1;
}
// 入栈 --push
public void push(int value){
// 先判断栈是否满
if (isFull()){
System.out.println("栈满");
return;
}
top++;
stack[top] = value;
}
// 出栈 -pop,将栈顶的数据返回
public int pop(){
// 先判断是否为空
if (isEmpty()){
// 抛出异常
throw new RuntimeException("栈空,没有数据");
}
int value = stack[top];
top--;
return value;
}
// 显示栈的情况[遍历栈],遍历时,需要从栈顶开始显示数据
public void list(){
if (isEmpty()){
System.out.println("栈空,没有数据");
return;
}
// 需要从栈顶开始显示数据
for (int i = top; i >= 0 ; i--) {
System.out.printf("stack[%d]=%d\n",i,stack[i]);
}
}
// 返回运算符的优先级,优先级使用数字来表示
// 数字越大,优先级越高
public int priority(int oper){
if (oper == '*'||oper == '/'){
return 1;
}else if (oper == '+'||oper == '-'){
return 0;
}else {
return -1; // 假定目前的表达式只有+,-,*,/
}
}
// 判断是不是一个运算符
public boolean isOper(char val){
return val == '+' || val == '-' || val == '*' || val == '/';
}
// 计算方法
public int cal(int num1,int num2,int oper){
int res = 0; // 用于存放计算的结果
switch (oper){
case '+':
res = num1 + num2;
break;
case '-':
res = num2 - num1;
break;
case '*':
res = num2 * num1;
break;
case '/':
res = num2 / num1;
break;
default:
break;
}
return res;
}
}
前缀 中缀 后缀(逆波兰)表达式
前缀表达式(波兰表达式)


中缀

后缀(逆波兰表达式)

逆波兰计算器

代码实现
package com.cbx.stack;
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/**
* @author cbx
* @date 2021/12/7
* @apiNote
*/
public class PolandNotation {
public static void main(String[] args) {
// 先定义一个逆波兰表达式
//(3+4)*5-6 => 3 4 + 5 * 6 -
// 为了方便 中间用空格隔开
// String suffixExpression = "3 4 + 5 * 6 -";
String suffixExpression = "4 5 * 8 - 60 + 8 2 / +";
// 1 现将suffixExpression 放到一个ArrayList中
// 2 将ArrayList 传递一个方法 遍历ArrayList 配合栈 完成计算
List<String> list = getListString(suffixExpression);
System.out.println("rpnList="+list);
int res = calculate(list);
System.out.println("计算的结果是="+res);
}
// 将一个逆波兰表达式,依次将数据和运算符放入到ArrayList中
public static List<String> getListString(String suffixExpression){
// 将suffixExpression分割
String[] split = suffixExpression.split(" ");
List<String> list = new ArrayList<>();
for (String ele : split) {
list.add(ele);
}
return list;
}
// 完成对逆波兰表达式的运算
// 1.从左至右扫描,将 3 和 4 压入堆栈;
// 2.遇到+运算符,因此弹出 4 和 3(4 为栈顶元素,3 为次顶元素),计算出 3+4 的值,得 7,再将 7 入栈;
// 3.将 5 入栈;
// 4.接下来是×运算符,因此弹出 5 和 7,计算出 7×5=35,将 35 入栈;
// 5.将 6 入栈;
// 6.最后是-运算符,计算出 35-6 的值,即 29,由此得出最终结果
public static int calculate(List<String> ls){
// 创建一个栈,只需要一个栈即可
Stack<String> stack = new Stack<String>();
// 遍历ls
for (String item : ls) {
// 这里使用正则表达式来取数
if (item.matches("\\d+")){ // 匹配的是多位数
// 入栈
stack.push(item);
}else { // 如果是运算符
// pop出两个数,并运算,再入栈
int num2 = Integer.parseInt(stack.pop());
int num1 = Integer.parseInt(stack.pop());
int res = 0;
if (item.equals("+")){
res = num1+num2;
}else if (item.equals("-")){
res = num1-num2;
}else if (item.equals("*")){
res = num1*num2;
}else if (item.equals("/")){
res = num1/num2;
}else {
throw new RuntimeException("运算符有误");
}
// 把res入栈
stack.push(""+res);
}
}
// 最后留在stack中的数据是运算结果
return Integer.parseInt(stack.pop());
}
}
中缀表达式转换为后缀表达式



代码实现
package com.cbx.stack;
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/**
* @author cbx
* @date 2021/12/7
* @apiNote
*/
public class PolandNotation {
public static void main(String[] args) {
// 完成将中缀表达式转成后缀代达式的功能
// 1. 1+((2+3)*4)-5 => 1 2 3 + 4 * + 5 -
// 2. 因为直接对Str 进行操作不方便 因此 先将 1+((2+3)*4)-5 转成中缀表达式对应的List
// 即 ArrayList [1,+,(,(,2,+,3,),*,4,),-,5]
// 3. 将得到的中缀表达式的list => 后缀表达式的List
// 4. ArrayList [1,+,(,(,2,+,3,),*,4,),-,5] => ArrayList [1,2,3,+,4,*,+,5]
String expression = "1+((2+3)*4)-5";
List<String> infixExpressionList = toInfixExpressionList(expression);
System.out.println("中缀表达式:"+infixExpressionList); // ArrayList[1,+,(,(,2,+,3,),*,4,),-,5]
List<String> suffixExpressionList = parseSuffixExpressionList(infixExpressionList);
System.out.println("后缀表达式:"+suffixExpressionList);
System.out.println("expression="+calculate(suffixExpressionList));
// 先定义一个逆波兰表达式
//(3+4)*5-6 => 3 4 + 5 * 6 -
// 为了方便 中间用空格隔开
// String suffixExpression = "3 4 + 5 * 6 -";
/* String suffixExpression = "4 5 * 8 - 60 + 8 2 / +";
// 1 现将suffixExpression 放到一个ArrayList中
// 2 将ArrayList 传递一个方法 遍历ArrayList 配合栈 完成计算
List<String> list = getListString(suffixExpression);
System.out.println("rpnList="+list);
int res = calculate(list);
System.out.println("计算的结果是="+res);*/
}
// 将得到的中缀表达式的list => 后缀表达式的List ls=ArrayList [1,+,(,(,2,+,3,),*,4,),-,5]=>ArrayList[1,2,3,+,4,*,+,5,-]
public static List<String> parseSuffixExpressionList(List<String> ls){
// 定义两个栈
Stack<String> s1 = new Stack<String>(); // 符号栈
// 第二个栈 在整个转换过程中 没有pop操作, 而且后面我们号需要逆序输出 还要逆序输出 我们同 List<String> s2 代替
// Stack<String> s2 = new Stack<String>();
List<String> s2 = new ArrayList<String>(); // 储存中间结果的List s2
// 遍历ls
for (String item : ls) {
// 如果是一个数,加入s2
if (item.matches("\\d+")){
s2.add(item);
}else if(item.equals("(")){
s1.push(item);
}else if (item.equals(")")){
// 如果是右括号,则依次弹出s1栈顶的运算符,并压入s2,直到遇到左括号为止,此时将这一对括号丢及
while (!s1.peek().equals("(")){
s2.add(s1.pop());
}
s1.pop();// !! 将( 弹出s1栈,消除小括号
}else {
// 当item的优先级 小于 s1栈顶的运算符的优先级 将 s1 栈顶的运算符弹出并加入到 s2 中,再次转到(4.1)与 s1 中新的栈顶运算符相比较
while (s1.size()!=0 && Operation.getValue(s1.peek())>=Operation.getValue(item)){
s2.add(s1.pop());
}
// 还需要将item压入栈
s1.add(item);
}
}
// 将s1中剩余的运算符压入到s2
while (s1.size()!=0){
s2.add(s1.pop());
}
return s2; // 注意因为是存放到List,因此按顺序输出就是对应的后缀表达式对应的List
}
// 将 中缀表达式转成对应的List
public static List<String> toInfixExpressionList(String s){
// 定义一个ArrayList 存放中缀表达式的内容
List<String> ls = new ArrayList<String >();
int i = 0;
String str; // 做对多位数的拼接
char c; // 每遍历到一个字符放入c中
do {
// 如果c是一个非数字 直接加入到ls
if ((c=s.charAt(i))<48||(c=s.charAt(i))>57){
ls.add(""+c);
i++;
}else {// 如果是一个数 需要考虑多位数的问题
str = ""; // str 置空
while(i<s.length() && (c=s.charAt(i))>=48&&(c=s.charAt(i))<=57){
str += c;// 拼接
i++;
}
ls.add(str);
}
}while (i < s.length());
return ls;
}
// 将一个逆波兰表达式,依次将数据和运算符放入到ArrayList中
public static List<String> getListString(String suffixExpression){
// 将suffixExpression分割
String[] split = suffixExpression.split(" ");
List<String> list = new ArrayList<>();
for (String ele : split) {
list.add(ele);
}
return list;
}
// 完成对逆波兰表达式的运算
// 1.从左至右扫描,将 3 和 4 压入堆栈;
// 2.遇到+运算符,因此弹出 4 和 3(4 为栈顶元素,3 为次顶元素),计算出 3+4 的值,得 7,再将 7 入栈;
// 3.将 5 入栈;
// 4.接下来是×运算符,因此弹出 5 和 7,计算出 7×5=35,将 35 入栈;
// 5.将 6 入栈;
// 6.最后是-运算符,计算出 35-6 的值,即 29,由此得出最终结果
public static int calculate(List<String> ls){
// 创建一个栈,只需要一个栈即可
Stack<String> stack = new Stack<String>();
// 遍历ls
for (String item : ls) {
// 这里使用正则表达式来取数
if (item.matches("\\d+")){ // 匹配的是多位数
// 入栈
stack.push(item);
}else { // 如果是运算符
// pop出两个数,并运算,再入栈
int num2 = Integer.parseInt(stack.pop());
int num1 = Integer.parseInt(stack.pop());
int res = 0;
if (item.equals("+")){
res = num1+num2;
}else if (item.equals("-")){
res = num1-num2;
}else if (item.equals("*")){
res = num1*num2;
}else if (item.equals("/")){
res = num1/num2;
}else {
throw new RuntimeException("运算符有误");
}
// 把res入栈
stack.push(""+res);
}
}
// 最后留在stack中的数据是运算结果
return Integer.parseInt(stack.pop());
}
}
// 编写一个类,可以返回一个运算符对应的优先级
class Operation{
private static int ADD = 1;
private static int SUB = 1;
private static int MUL = 2;
private static int DIV = 2;
// 写一个方法,返回对应的优先级数字
public static int getValue(String operation){
int result = 0;
switch (operation){
case "+":
result = ADD;
break;
case "-":
result = SUB;
break;
case "*":
result = MUL;
break;
case "/":
result = DIV;
break;
default:
System.out.println("不存在该运算符");
break;
}
return result;
}
}
递归

递归可以解决的问题

递归的重要规则

迷宫问题

代码实现
package com.cbx.recursion;
/**
* @author cbx
* @date 2021/12/9
* @apiNote
*/
public class MiGong {
public static void main(String[] args) {
// 先创建一个二维数组,模拟迷宫
// 地图
int[][] map = new int[8][7];
// 使用1 表示墙
// 上去全部置为1
for (int i = 0; i < 7; i++) {
map[0][i] = 1;
map[7][i] = 1;
}
// 左右全部置为1
for (int i = 0; i < 8; i++) {
map[i][0] = 1;
map[i][6] = 1;
}
// 设置挡板,1表示
map[3][1] = 1;
map[3][2] = 1;
//map[1][2] = 1;
//map[2][2] = 1;
// 输出地图
System.out.println("地图的情况");
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 7; j++) {
System.out.print(map[i][j]+" ");
}
System.out.println();
}
// 使用递归回溯给小球找路
setWay(map,1,1);
// 输出新的地图,小球走过,并标识过的递归
System.out.println("小球走过,并标识过的 地图的情况");
for (int i = 0; i < 8; i++) {
for (int j = 0; j < 7; j++) {
System.out.print(map[i][j]+" ");
}
System.out.println();
}
}
// 使用递归回溯给小球找路
// 说明 map是地图
// i,j表示从哪个位置开始出发(i,j)
// 如果小球到map[6][5] = 则说明通路找到
// 约定 当map[i][j] 为0时 表示该点没有走过 1为墙 2为通路(小球行径路径) 3为该位置已经走过 但是走不通
// 再走迷宫时 需要确定一个策略(行径方向 当走不通时往策略的下一个方向) 下->右->上->左 ,如果该点都走不通 在回溯
/**
*
* @param map 地图
* @param i 从哪个位置开始找
* @param j
* @return 如果找到通路 返回true 否则为false
*/
public static boolean setWay(int[][] map, int i, int j){
if (map[6][5] == 2){// 通路已经找到OK
return true;
}else {
if (map[i][j] == 0){ // 如果当前这个点还没有走过
// 按照策略 下->右->上->左 走
map[i][j] = 2; // 假定该点可以走通,
if (setWay(map,i+1,j)){ // 向下走
return true;
} else if (setWay(map,i,j+1)){// 向右走
return true;
} else if (setWay(map,i-1,j)){ // 向上走
return true;
} else if (setWay(map,i,j-1)){ // 向左走
return true;
} else {
// 说明该点是走不通,是死路
map[i][j] = 3;
return false;
}
}else {
// 如果map[i][j] != 0,可能是1,2,3
return false;
}
}
}
}
最短路径分析
目前比较笨的方法 上下左右四个方向 设置所有的策略方法 (上下左右 、上下右左、上左下右 。。。24种) 都走一次 找到最短的那个策略
八皇后问题



代码实现
package com.cbx.recursion;
/**
* @author cbx
* @date 2021/12/10
* @apiNote
*/
public class Queen8 {
// 定义一个max表示共有多少个皇后
int max = 8;
// 定义数组array,保存皇后放置位置的结果,比如arr = {0,4,7,5,2,6,1,3}
int[] array = new int[max];
static int count = 0;
static int judgeCount = 0;
public static void main(String[] args) {
// 测试一把
Queen8 queen8 = new Queen8();
queen8.check(0);
System.out.println("一共有"+count+"个解法");
System.out.println("一共判断了"+judgeCount+"次冲突");
}
// 编写一个方法,放置第n+1个皇后,n从0开始
// 特别注意: check 是 每一次递归时, 进入到check中都有 for(int i = 0;i < max;i++),因此会有回溯
private void check(int n){
if (n == max){ // n=8,表示已经放了8个皇后了
print();
return;
}
// 依次放入皇后,并判断是否冲突
for (int i = 0; i < max; i++) {
// 先把当前这个皇后n,放到该行的第一列
array[n] = i;
// 判断当放置第n个皇后到i列时,是否冲突
if (judge(n)){ // 不冲突
// 接着放第n+1个皇后,即开始递归
check(n+1); //
}
// 如果冲突,就继续执行 array[n] = i;即将第n个皇后,放置在本行的后移的一个位置,i++
}
}
// 查看当我们放置第n个皇后,就去检测该皇后是否和前面已经放置的皇后冲突
/**
*
* @param n 表示第n+1个皇后,n从0开始
* @return
*/
private boolean judge(int n){
judgeCount++;
for (int i = 0; i < n; i++) {
// 说明
// 1. array[i] == array[n] 表示判断第n个皇后是否和前面的n-1个皇后在同一列
// 2. Math.abs(n-i) == Math.abs(array[n]-array[i]) 表示判断第n个皇后是否和第i皇后是否在同一斜线
// n = 1 放置第2列 n = 1 array[1] = 1
// Math.abs(1-0) == 1 Math.abs(array[n] - array[i]) = Math.abs(1-0) = 1
// 3. 判断是否在同一行,没有必要判断,因为n每次都在递增,i永远小于n
if (array[i] == array[n] || Math.abs(n-i) == Math.abs(array[n]-array[i])){
return false;
}
}
return true;
}
// 写一个方法,可以将皇后摆放的位置输出
private void print(){
count++;
for (int i = 0; i < array.length; i++) {
System.out.print(array[i]+" ");
}
System.out.println();
}
}
排序算法

时间复杂度

时间频度


结论
1. 2n+20 和 2n 随着 n 变大,执行曲线无限接近, 20 可以忽略
2. 3n+10 和 3n 随着 n 变大,执行曲线无限接近, 10 可以忽略

结论
1. 2n^2+3n+10 和 2n^2 随着 n 变大, 执行曲线无限接近, 可以忽略 3n+10
2. n^2+5n+20 和 n^2 随着 n 变大,执行曲线无限接近, 可以忽略 5n+20
忽略系数(3次方及以上不能忽略)

时间复杂度










空间复杂度

冒泡排序
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始), 依次比较 相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就象水底下的气泡一样逐渐向上冒。
优化: 因为排序的过程中,各元素不断接近自己的位置, 如果一趟比较下来没有进行过交换 , 就说明序列有序,因此要在 排序过程中设置一个标志 flag 判断元素是否进行过交换。从而减少不必要的比较。(这里说的优化,可以在冒泡排 序写好后,在进行)

代码实现(步骤)
package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/11
* @apiNote
*/
public class BubbleSort {
public static void main(String[] args) {
int arr[] = {3,9,-1,10,-2};
// 展示冒泡排序的演变过程 比较arr.length-1 次 就可以得出结果
/**
* 第一趟排序后的数组
* [3, -1, 9, -2, 10]
* 第二趟排序后的数组
* [-1, 3, -2, 9, 10]
* 第三趟排序后的数组
* [-1, -2, 3, 9, 10]
* 第四趟排序后的数组
* [-2, -1, 3, 9, 10]
*/
// 第一趟排序 就是将最大的数字放到最后
int temp = 0; // 临时变量
for(int j = 0; j < arr.length - 1; j++ ){
if(arr[j] > arr[j + 1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = temp;
}
}
System.out.println("第一趟排序后的数组");
System.out.println(Arrays.toString(arr));
// 第二趟排序 , 把第二大的数放在倒数第二位 最后一个数字不参与排序
for(int j = 0; j < arr.length - 2; j++ ){
if(arr[j] > arr[j + 1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = temp;
}
}
System.out.println("第二趟排序后的数组");
System.out.println(Arrays.toString(arr));
// 第三趟排序 , 把第三大的数放在倒数第三位 最后两个数字不参与排序
for(int j = 0; j < arr.length - 3; j++ ){
if(arr[j] > arr[j + 1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = temp;
}
}
System.out.println("第三趟排序后的数组");
System.out.println(Arrays.toString(arr));
// 第四趟排序 , 把第四大的数放在倒数第四位 最后三个数字不参与排序
for(int j = 0; j < arr.length - 4; j++ ){
if(arr[j] > arr[j + 1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = temp;
}
}
System.out.println("第四趟排序后的数组");
System.out.println(Arrays.toString(arr));
}
}
整合后的代码
// 冒泡排序
int temp = 0; // 临时变量
for (int i = 0; i < arr.length-1; i++) {
for(int j = 0; j < arr.length - 1-i; j++ ){
if(arr[j] > arr[j + 1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = temp;
}
}
System.out.println("第"+(i+1)+"趟排序后的数组");
System.out.println(Arrays.toString(arr));
}
时间复杂度为O(n^2)
冒泡排序的优化
// 将前面的冒泡排序算法,封装成一个方法
public static void bubbleSort(int[] arr){
// 冒泡排序
int temp = 0; // 临时变量
boolean flag = false; // 标识变量,表示是否进行过交换
for (int i = 0; i < arr.length-1; i++) {
for(int j = 0; j < arr.length - 1-i; j++ ){
if(arr[j] > arr[j + 1]){
flag = true;
temp = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = temp;
}
}
// System.out.println("第"+(i+1)+"趟排序后的数组");
// System.out.println(Arrays.toString(arr));
if (!flag){ // 在一趟排序中,一次交换都没有发生过
break;
}else {
flag = false; // 重置flag,进行下一趟判断
}
}
}
韩老师的电脑大概20秒处理8万个随机数
选择排序算法


代码实现

package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/12
* @apiNote
*/
public class SelectSort {
public static void main(String[] args) {
int[] arr = {101,34,119,1,23,121};
System.out.println("排序前~~");
System.out.println(Arrays.toString(arr));
selectSort(arr);
System.out.println("排序后~~");
System.out.println(Arrays.toString(arr));
}
// 选择排序
public static void selectSort(int[] arr){
// 在推导的过程中,发现规律,因此,可以使用for来解决
for (int i = 0; i <arr.length-1; i++) {
int minIndex = i;
int min = arr[i];
for (int j = i + 1; j < arr.length; j++) {
if (min > arr[j]){ // 说明假定的最小值,并不是最小
min = arr[j]; // 重置min
minIndex = j; // 重置minIndex
}
}
// 将最小值,放在arr[0],即交换
if (minIndex!=i){
arr[minIndex] = arr[i];
arr[i] = min;
}
// System.out.println("第"+(i+1)+"轮后~~");
// System.out.println(Arrays.toString(arr));
}
/* // 使用逐步推导的方式,来讲解选择排序
// 第1轮
// 原始的数组: 101,34,119,1
// 第一轮排序: 1,34,119,101
// 算法 先简单--> 做复杂,就是可以把一个复杂的算法,拆分成简单的问题->逐步解决
int minIndex = 0;
int min = arr[0];
for (int j = 0 + 1; j < arr.length; j++) {
if (min > arr[j]){ // 说明假定的最小值,并不是最小
min = arr[j]; // 重置min
minIndex = j; // 重置minIndex
}
}
// 将最小值,放在arr[0],即交换
if (minIndex!=0){
arr[minIndex] = arr[0];
arr[0] = min;
}
System.out.println("第1轮后~~");
System.out.println(Arrays.toString(arr));
// 第2轮
minIndex = 1;
min = arr[1];
for (int j = 1 + 1; j < arr.length; j++) {
if (min > arr[j]){ // 说明假定的最小值,并不是最小
min = arr[j]; // 重置min
minIndex = j; // 重置minIndex
}
}
// 将最小值,放在arr[0],即交换
if (minIndex!=1){
arr[minIndex] = arr[1];
arr[1] = min;
}
System.out.println("第2轮后~~");
System.out.println(Arrays.toString(arr));
// 第3轮
minIndex = 2;
min = arr[2];
for (int j = 2 + 1; j < arr.length; j++) {
if (min > arr[j]){ // 说明假定的最小值,并不是最小
min = arr[j]; // 重置min
minIndex = j; // 重置minIndex
}
}
// 将最小值,放在arr[0],即交换
if (minIndex!=2){
arr[minIndex] = arr[2];
arr[2] = min;
}
System.out.println("第3轮后~~");
System.out.println(Arrays.toString(arr));
*/
}
}
时间复杂度O(n^2)
韩老师的电脑处理8万个随机数大概3秒
插入排序法


代码实现
有一群小牛, 考试成绩分别是 101, 34, 119, 1 请从小到大排序
package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/12
* @apiNote
*/
public class InsertSort {
public static void main(String[] args) {
int[] arr = {101,34,119,1,-1,89};
System.out.println("插入排序前~~");
System.out.println(Arrays.toString(arr));
insertSort(arr);
System.out.println("插入排序后~~");
System.out.println(Arrays.toString(arr));
}
// 插入排序
public static void insertSort(int[] arr){
int insertVal = 0;
int insertIndex = 0;
// 使用for循环简化代码
for (int i = 1; i < arr.length; i++) {
// 定义待插入的数
insertVal = arr[i];
insertIndex = i-1; // 即arr[1]的前面这个数的下标
// 给insertVal找到插入的位置
// 说明
// 1. insertIndex >= 0 保证在给insertVal找插入位置时,不越界
// 2. insertVal < arr[insertIndex] 待插入的数,还没有找到插入位置
// 3. 就需要将arr[insertIndex]后移
while (insertIndex >= 0 && insertVal < arr[insertIndex]){
arr[insertIndex+1] = arr[insertIndex];// arr[insertIndex]
insertIndex--;
}
// 当退出while循环时,说明插入的位置找到,insertIndex+1
// 判断一下是否需要赋值
if (insertIndex + 1 != i){
arr[insertIndex+1] = insertVal;
}
/* System.out.println("第"+i+"轮插入");
System.out.println(Arrays.toString(arr));*/
}
/* // 使用逐步推论的方式
// 第1轮{101,34,119,1}=>{34,101,119,1}
// 定义待插入的数
int insertVal = arr[1];
int insertIndex = 1-1; // 即arr[1]的前面这个数的下标
// 给insertVal找到插入的位置
// 说明
// 1. insertIndex >= 0 保证在给insertVal找插入位置时,不越界
// 2. insertVal < arr[insertIndex] 待插入的数,还没有找到插入位置
// 3. 就需要将arr[insertIndex]后移
while (insertIndex >= 0 && insertVal < arr[insertIndex]){
arr[insertIndex+1] = arr[insertIndex];// arr[insertIndex]
insertIndex--;
}
// 当退出while循环时,说明插入的位置找到,insertIndex+1
arr[insertIndex+1] = insertVal;
System.out.println("第1轮插入");
System.out.println(Arrays.toString(arr));
// 第2轮
insertVal = arr[2];
insertIndex = 2 - 1;
while (insertIndex >= 0 && insertVal < arr[insertIndex]){
arr[insertIndex+1] = arr[insertIndex];// arr[insertIndex]
insertIndex--;
}
arr[insertIndex+1] = insertVal;
System.out.println("第2轮插入");
System.out.println(Arrays.toString(arr));
// 第3轮
insertVal = arr[3];
insertIndex = 3 - 1;
while (insertIndex >= 0 && insertVal < arr[insertIndex]){
arr[insertIndex+1] = arr[insertIndex];// arr[insertIndex]
insertIndex--;
}
arr[insertIndex+1] = insertVal;
System.out.println("第3轮插入");
System.out.println(Arrays.toString(arr));*/
}
}
时间复杂度O(n^2)
韩老师的电脑 8万个随机数排序 大致5秒
希尔排序算法图解
简单插入排序的问题

希尔排序是插入排序的一种高效版本


代码实现(交换法)
效率并不是很高 韩老师的电脑对8万个随机数进行排序 花了17秒
package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/13
* @apiNote
*/
public class ShellSort {
public static void main(String[] args) {
int[] arr = {8,9,1,7,2,3,5,4,6,0};
shellSort(arr);
}
// 使用逐步推导的方式
// 希尔排序时,对有序序列在插入时用交换法
// 思路(算法)---> 代码
public static void shellSort(int[] arr){
int temp = 0;
int count = 0;
// 根据下面的逐步分析,使用循环处理
for (int gap = arr.length / 2; gap > 0; gap /= 2 ) {
for (int i = gap; i < arr.length; i++) {
// 遍历各组中所有的元素(共gap组),步长gap
for (int j = i-gap; j >= 0 ; j -= gap) {
// 如果当前元素大于加长步长后的元素,说明交换
if (arr[j] > arr[j+gap]){
temp = arr[j];
arr[j] = arr[j+gap];
arr[j+gap] = temp;
}
}
}
System.out.println("希尔排序第"+(++count)+"轮后="+ Arrays.toString(arr));
}
/* // 希尔排序的第一轮排序
// 因为第一轮排序,是将10个数据排序分为了5组
for (int i = 5; i < arr.length; i++) {
// 遍历各组中所有的元素(共5组,每组有2个元素),步长5
for (int j = i-5; j >= 0 ; j -= 5) {
// 如果当前元素大于加长步长后的元素,说明交换
if (arr[j] > arr[j+5]){
temp = arr[j];
arr[j] = arr[j+5];
arr[j+5] = temp;
}
}
}
System.out.println("希尔排序1轮后="+ Arrays.toString(arr));
// 希尔排序的第2轮排序
// 因为第2轮排序,是将10个数据排序分为了5/2=2组
for (int i = 2; i < arr.length; i++) {
// 遍历各组中所有的元素(共5组,每组有2个元素),步长5
for (int j = i-2; j >= 0 ; j -= 2) {
// 如果当前元素大于加长步长后的元素,说明交换
if (arr[j] > arr[j+2]){
temp = arr[j];
arr[j] = arr[j+2];
arr[j+2] = temp;
}
}
}
System.out.println("希尔排序2轮后="+ Arrays.toString(arr));
// 希尔排序的第3轮排序
// 因为第3轮排序,是将10个数据排序分为了2/2 = 1组
for (int i = 1; i < arr.length; i++) {
// 遍历各组中所有的元素(共5组,每组有2个元素),步长5
for (int j = i-1; j >= 0 ; j -= 1) {
// 如果当前元素大于加长步长后的元素,说明交换
if (arr[j] > arr[j+1]){
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
System.out.println("希尔排序3轮后="+ Arrays.toString(arr));*/
}
}
代码实现(移位法)
效率较高 韩老师的电脑对8万个随机数进行排序 花了1秒
// 对交换式的希尔排序进行优化->移位法
public static void shellSort2(int[] arr){
// 增量gap,并逐步的缩小增量
for (int gap = arr.length / 2; gap > 0; gap /= 2 ) {
// 从第gap个元素,逐个对其所在的组进行直接插入排序
for (int i = gap; i < arr.length; i++) {
int j = i;
int temp = arr[j];
if (arr[j] < arr[j-gap]){
while (j - gap >= 0 && temp < arr[j-gap]){
// 移动
arr[j] = arr[j-gap];
j -= gap;
}
// 当退出while后,就给temp找到插入的位置
arr[j] = temp;
}
}
}
}
时间复杂度O(n^(1.3—2))
快速排序算法
第一种方式

package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/14
* @apiNote
*/
public class QuickSort {
public static void main(String[] args) {
int[] arr = {-9,78,0,23,-567,70,70,70};
quickSort(arr,0,arr.length-1);
System.out.println("arr: "+ Arrays.toString(arr));
}
/**
*
* @param arr
* @param left
* @param right
*/
public static void quickSort(int[] arr,int left,int right){
int l = left;// 左下标
int r = right; // 右下标
int temp = 0; // 临时变量
// pivot 中轴
int pivot = arr[(left+right)/2];
// 只要右边的索引大于左边的索引就继续循环 目的是 让 比pivot小的值放到左边 比 pivot 值大的放在右边
while (l<r){
// 在pivot的左边 一直找 找到大于等于pivot的值 ,才退出
while (arr[l] < pivot){//最多找到pivot本身
l++;
}
// 在pivot的左边 一直找 找到小于等于pivot的值 ,才退出
while (arr[r] > pivot){//最多找到pivot本身
r--;
}
// 如果成立 说明 pivot 左边的值, 已经全部小于等于pivot的值, 右边, 已经全部大于等于pivot的值
if(l>=r){
break;
}
//交换
temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
// 判断 如果交换完后 发现arr[l] = pivot r向前移动 l--
if (arr[l] == pivot){
r -= 1;
}else if (arr[r] == pivot){// 判断 如果交换完后 发现arr[r] = pivot l向后移动 l++
l++;
}
}
// 如果 l == r 必须 l++ 和 r--, 否则会出现栈溢出
if (l == r ){
l++;
r--;
}
// 向左递归
if (left < r) {
quickSort(arr,left,r);
}
// 向右递归
if (right > l) {
quickSort(arr, l, right);
}
}
}
韩老师的电脑对8万个随机数进行排序 花了不到一秒 80w数据也不到1秒 800w 2-3秒
快排 时间复杂度O (nlogn) 但是空间复杂度较高
第二种方式
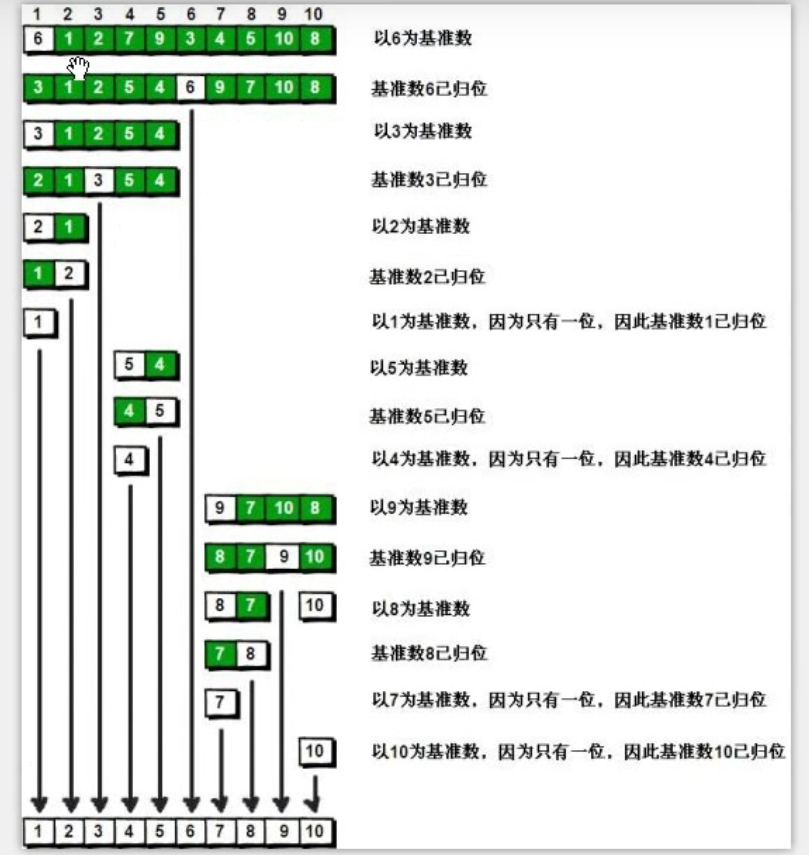
package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/14
* @apiNote
*/
public class QuickSort2 {
public static void main(String[] args) {
int[] arr = {-9,78,0,23,-567,70,70,70};
quickSort(arr,0,arr.length-1);
System.out.println("arr: "+ Arrays.toString(arr));
}
public static void quickSort(int[] arr,int left,int right){
// 进行判断,如果左边索引比右边索引要大,是不合法的,直接使用return结束这个方法
if (left > right){
return;
}
// 定义变量保存基准数
int base = arr[left];
// 定义变量i,指向最左边
int i = left;
// 定义变量j,指向最右边
int j = right;
int temp = 0;
// 当i和j不相遇时
while (i != j){
// 由j从右往左检索比基准数小的,如果检索到比基准数小的就停下
// 如果检索到比基准数大或者相等的,就继续检索
while (arr[j] >= base && i < j){
j--; // j从右往左移动
}
// i从左往右检索
while (arr[i] <= base && i < j){
i++; // i从左往右移动
}
// 代码走到这里,i停下了,j也停下。然后交换i和j位置的元素
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 如果上面while循环的条件不成立,会跳出这个循环,往下执行。
// 如果这个条件不成立说明i和j相遇了
// 如果i和j相遇了,就交换基准数这个元素和相遇位置的元素。
// 把相遇位置的元素赋值给基准数这个位置的元素
arr[left] = arr[i];
// 把基准数赋值给相遇位置的元素。
arr[i] = base;
// 基准数在这里就归位了,左边的数字都比他小,右边的都比他大
// 排基准数的左边
quickSort(arr,left,i - 1);
// 排右边
quickSort(arr,j + 1,right);
}
}
归并排序


代码实现
package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/15
* @apiNote
*/
public class MergeSort {
public static void main(String[] args) {
// int[] arr = {8,4,5,7,1,3,6,2};
int[] arr = new int[80000];
int[] temp = new int[arr.length]; // 归并排序需要额外的空间
for (int i = 0;i < 80000;i++){
arr[i] = (int) (Math.random()*8000000); // 生成一个[8,8000000)数
}
long before = System.currentTimeMillis();
mergeSort(arr,0, arr.length - 1,temp);
long after = System.currentTimeMillis();
System.out.println("耗时"+(after-before)+"ms");
// System.out.println("归并排序后: "+ Arrays.toString(arr));
}
// 分+合方法
public static void mergeSort(int[] arr,int left,int right,int[] temp){
if (left < right){
int mid = (left + right) / 2; // 中间索引
// 向左递归进行分解
mergeSort(arr,left,mid,temp);
// 向右递归进行分解
mergeSort(arr,mid+1,right,temp);
// 合并
merge(arr,left,mid,right,temp);
}
}
// 合并的方法
/**
*
* @param arr 排序的原始数组
* @param left 左边有序序列的初始索引
* @param mid 中间索引
* @param right 右边索引
* @param temp 做中转的数组
*/
public static void merge(int[] arr,int left,int mid,int right,int[] temp){
int i = left; // 初始化i,左边有序序列的初始索引
int j = mid + 1; // 初始化j,右边有序序列的初始索引
int t = 0; // 指向temp数组的当前索引
//(一)
// 先把左右两边有序的数据按照规则填充到temp数组
// 直到左右两边的有序序列,有一边处理完毕为止
while(i <= mid && j <= right){// 继续
// 如果左边的有序序列的当前元素,小于等于右边有序序列的当前元素
// 即将左边的当前元素,填充到temp数组
// 然后t++,i++
if (arr[i] <= arr[j]){
temp[t] = arr[i];
t++;
i++;
}else { // 反之,将右边有序序列的当前元素,填充到temp数组
temp[t] = arr[j];
t++;
j++;
}
}
//(二)
// 把有剩余数据的一边的数据依次全部填充到temp
while(i <= mid){ // 左边的有序序列还有剩余的元素,就全部填充到temp
temp[t] = arr[i];
t++;
i++;
}
while (j <= right){
temp[t] = arr[j];
t++;
j++;
}
//(三)
// 将temps数组的元素拷贝到arr
// 注意,并不是每次都拷贝所有
t = 0;
int tempLeft = left;
// 第一次合并 tempLeft = 0,right = 1 // 第二次 tempLeft = 2,right = 3//第三次 tl = 0,ri=3
// 最后一次tempLeft = 0,right = 7
while (tempLeft <= right){
arr[tempLeft] = temp[t];
t++;
tempLeft++;
}
}
}
**时间复杂度O(nlogn) **
韩老师的电脑对8万个随机数进行排序 花了不到0-1秒 80w 一秒 800w3-4秒
基数排序 (桶排序)

稳定排序 : 如果要排序的数组有两个相同的数字 如a1 =a2 =1 {a1,2,3,a2} 排序后 {a1,a2,2,3} a1还是在a2的前面



代码实现
package com.cbx.sort;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/16
* @apiNote
*/
public class RadixSort {
public static void main(String[] args) {
int[] arr = {53,3,542,748,14,214};
// radixSort(arr);
radixSortAll(arr);
}
// 基数排序法
public static void radixSort(int[] arr){
// 模拟对一轮(针对每个元素的个位数进行排序处理)
// 定义一个二维数组,表示一个二维数组, 每个桶就是一个一维数组
// 说明 二维数组包含10个一维数组
// 为了防止放入数的时候 数据溢出 ,则每一个一维数组的大小为array.length()
// 很明显 空间换时间
int[][] bucket = new int[10][arr.length];
// 为了记录每个桶中 实际存放了多少个数据 我们定义一个一维数组来记录每个桶的个数
// 比如bucketElementCounts[0] 就是bucket[0] 的放入数据的个数
int[] bucketElementCounts = new int[10];
for (int j = 0; j < arr.length; j++) {
// 取出每个元素的个位
int digitOfElement = arr[j] % 10;
// 放入到对应的桶
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
// 将桶里的数据放入
int index = 0;
// 遍历每一个桶,将桶里面的数据放入,原来的数组中
for (int k = 0; k < bucket.length; k++) {
if (bucketElementCounts[k] != 0){
for (int j = 0; j < bucketElementCounts[k]; j++) {
arr[index++] = bucket[k][j];
}
}
// 第一轮需要对bucketElementCount数组置零
bucketElementCounts[k] = 0;
}
System.out.println("第一轮 对个位数进行处理后的数组: "+ Arrays.toString(arr));
// 模拟对二轮(针对每个元素的十位数进行排序处理)
for (int j = 0; j < arr.length; j++) {
// 取出每个元素的个位
int digitOfElement = arr[j] / 10 % 10;
// 放入到对应的桶
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
// 将桶里的数据放入
index = 0;
// 遍历每一个桶,将桶里面的数据放入,原来的数组中
for (int k = 0; k < bucket.length; k++) {
if (bucketElementCounts[k] != 0){
for (int j = 0; j < bucketElementCounts[k]; j++) {
arr[index++] = bucket[k][j];
}
}
// 第一轮需要对bucketElementCount数组置零
bucketElementCounts[k] = 0;
}
System.out.println("第二轮 对十位数进行处理后的数组: "+ Arrays.toString(arr));
// 模拟对三轮(针对每个元素的百位数进行排序处理)
for (int j = 0; j < arr.length; j++) {
// 取出每个元素的个位
int digitOfElement = arr[j] / 100 % 10;
// 放入到对应的桶
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
// 将桶里的数据放入
index = 0;
// 遍历每一个桶,将桶里面的数据放入,原来的数组中
for (int k = 0; k < bucket.length; k++) {
if (bucketElementCounts[k] != 0){
for (int j = 0; j < bucketElementCounts[k]; j++) {
arr[index++] = bucket[k][j];
}
}
// 第一轮需要对bucketElementCount数组置零
bucketElementCounts[k] = 0;
}
System.out.println("第三轮 对百位数进行处理后的数组: "+ Arrays.toString(arr));
}
// 总的基数排序
public static void radixSortAll(int[] arr){
int[][] bucket = new int[10][arr.length];
int[] bucketElementCounts = new int[10];
int index;
// 需要获取最大的数
int max = arr[0];
for (int i = 1; i < arr.length; i++){
if (max < arr[i]){
max = arr[i];
}
}
int maxLength = (max+"").length();
for (int i = 0, n = 1; i < maxLength; i++, n *=10) {
for (int j = 0; j < arr.length; j++){
int digitOfElement = arr[j] / n % 10;
// 放入到对应的桶
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
// 将桶里的数据放入
index = 0;
// 遍历每一个桶 将桶里的数据放入 原来的数组中
for (int k = 0;k < bucket.length; k++){
if (bucketElementCounts[k] != 0){
for (int j = 0; j < bucketElementCounts[k]; j++){
arr[index++] = bucket[k][j];
}
}
bucketElementCounts[k]= 0;
}
}
System.out.println("基数排序的结果" + Arrays.toString(arr));
}
}
**时间复杂度O(nlogn) 韩老师的电脑对8万个随机数进行排序 花了不到0-1秒 80w 1秒不到 800w1秒 **
**8000w 80000000 11 4 /1024/1024/1024 = 3.3G的内存

如果有负数就不使用基数排序
八大排序算法的对比

堆排序要学了二叉树才能理解
查找算法

顺序(线性)查找
有序无序数组都可以使用线性查找
代码实现
package com.cbx.search;
/**
* @author cbx
* @date 2021/12/17
* @apiNote
*/
public class SeqSearch {
public static void main(String[] args) {
int[] arr = {1,9,11,-1,34,89}; // 没有顺序的数组
int i = seqSearch(arr, 11);
if (i!=-1){
System.out.println("找到了,下标是"+i);
}else {
System.out.println("未找到");
}
}
public static int seqSearch(int[] arr,int value){
// 线性查找是逐一比对,发现有相同值,就返回下标
for (int i = 0; i < arr.length; i++) {
if (arr[i] == value){
return i;
}
}
return -1;
}
}
二分查找算法


代码实现(要求数组有序)
package com.cbx.search;
import java.util.ArrayList;
import java.util.List;
/**
* @author cbx
* @date 2021/12/17
* @apiNote
*/
public class BinarySearch {
public static void main(String[] args) {
int[] arr = {1,8,10,89,1000,1000,1000,1234};
System.out.println(binarySearch(arr, 0, arr.length-1, 10));
System.out.println(binarySearchUpgrade(arr, 0, arr.length-1, 1000));
}
// 二分查找算法
/**
*
* @param arr 数组
* @param left 查找时 左边的索引
* @param right 查找时 右边的索引
* @param findVal 要查找的值
* @return 如果找到就返回下标 没找到返回 -1
*/
public static int binarySearch(int[] arr, int left, int right, int findVal){
int mid = (left + right) / 2;
int midVal = arr[mid];
if (left > right) return -1;// 没有找到
if(findVal > midVal){ // 向右递归
return binarySearch(arr, mid+1, right, findVal);
}else if(findVal < midVal){ // 向左递归
return binarySearch(arr, left, mid-1, findVal);
}else {
return mid;
}
}
// 对多个相同值的查找
// 思路分析 在找到mid的时候不要马上返回 向mid的索引的左/右边扫描 将所有满足的查找值1000的所有下标 放入数组中
public static List<Integer> binarySearchUpgrade(int[] arr, int left, int right, int findVal){
List<Integer> resIndexList = new ArrayList<>();
int mid = (left + right) / 2;
int midVal = arr[mid];
if (left > right) {
resIndexList.add(-1);// 没有找到
return resIndexList;
}
if(findVal > midVal){ // 向右递归
return binarySearchUpgrade(arr, mid+1, right, findVal);
}else if(findVal < midVal){ // 向右递归
return binarySearchUpgrade(arr, left, mid-1, findVal);
}else {
int temp = mid;
// 向左扫描
while (arr[--temp] == midVal){
resIndexList.add(temp);
}
resIndexList.add(mid);
temp = mid;
// 向右扫描
while (arr[++temp] == midVal){
resIndexList.add(temp);
}
return resIndexList;
}
}
}
插值查找法

代码实现(要求数组有序)
package com.cbx.search;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/18
* @apiNote
*/
public class InsertValueSearch {
public static void main(String[] args) {
int[] arr = new int[100];
for (int i = 0; i < 100; i++) {
arr[i] = i + 1;
}
System.out.println(Arrays.toString(arr));
System.out.println(insertValueSearch(arr,0,arr.length-1,55));
}
// 编写插值查找算法
/**
* 插值查找算法的前提要求也是数组要有序
* @param arr 传入的数组
* @param left 左边的索引
* @param right 右边的索引
* @param findVal 要查找的值
* @return
*/
public static int insertValueSearch(int[] arr,int left,int right,int findVal){
// System.out.println("插值查找方法~");
if (left > right || findVal < arr[0] || findVal > arr[arr.length - 1]){ // 优化查找,且防止越界
return -1;
}
// 求出mid
int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]);
int midVal = arr[mid];
if (findVal > midVal){ // 向右递归
return insertValueSearch(arr,mid + 1,right,findVal);
}else if (findVal < midVal){ // 向左递归
return insertValueSearch(arr,left,mid - 1,findVal);
}else {
return mid;
}
}
}
使用场景

斐波那契(黄金分割)查找算法


代码实现
package com.cbx.search;
import java.util.Arrays;
/**
* @author cbx
* @date 2021/12/18
* @apiNote
*/
public class FibonacciSearch {
public static int maxSize = 20;
public static void main(String[] args) {
int[] arr = {1,8,10,89,1000,1234};
System.out.println(fibSearch(arr, 1234));
}
// 因为后面我们mid = low+F(k - 1)-1. 需要使用斐波那契数列, 因此我们需要先获取到斐波那契数列
// 用非递归的方法得到一个大小为20的斐波那契数列
public static int[] fbn(){
int[] f = new int[maxSize];
f[0] = 1;
f[1] = 1;
for (int i = 2; i < maxSize; i++) {
f[i] = f[i-1] + f[i-2];
}
return f;
}
// 非递归的方式编写斐波那契数列查找算法
/**
*
* @param a
* @param key 需要查找的值
* @return 返回对应的下标 没有则返回-1
*/
public static int fibSearch(int[] a, int key){
int low = 0;
int high = a.length -1;
int k = 0; // 表示斐波那契分割数值的下标 mid = low+F(k - 1)-1
int mid = 0;
int[] f = fbn(); // 获取斐波那契数列
// 获取斐波那契分割数值的下标
while (high > f[k]-1){
k++;
}
// 因为 f[k] 可能大于数组a 的长度 需要一个Array类 构造一个新的数组 并指向temp[]
int[] temp = Arrays.copyOf(a, f[k]); // 多出来的部分用0补起来
// 实际上需要使用a最后的数填充temp
// 举例 :
// temp:{1,8,10,89,1000,1234,0,0} =>temp:{1,8,10,89,1000,1234,1234,1234}
for (int i = high + 1;i < temp.length; i++){
temp[i] = a[high];
}
// 使用while循环查找我们的key
while (low <= high) {
mid = low + f[k-1]-1;
if (key < temp[mid]){//说明应该向数组的前一部分查找(左边)
high = mid -1;
// 为什么是k--
// 1 全部元素 = 前面的元素 + 后边的元素
// 2 f[k] = f[k-1] + f[k-2];
// 因为前面有f[k-1]个元素,所以我们继续拆分 f[k-1] = f[k-2] + f[k-3];
// 即在f[k-1] 的前面继续查找 k--
// 即下次在循环的时候 mid = f[k-1-1] -1
k--;
}else if ( key > temp[mid]){ // 我们继续向数组的右边查找
low = mid + 1;
// 为什么是k-2
// 1 全部元素 = 前面的元素 + 后边的元素
// 2 f[k] = f[k-1] + f[k-2];
// 3 因为后面有f[k-2] 所以加足拆分 f[k -2] = f[k-3] + f[k-4];
// 4 即在f[k-2] 的前面继续查找
// 下次循环mid = f[k-1-2] -1
k -= 2;
}else { // 找到
// 需要确定返回的是哪个下标
if (mid <= high){
return mid;
}else {
return high;
}
}
}
return -1; // 没有找到
}
}
哈希表



代码实现
package com.cbx.hashtab;
import java.util.Scanner;
/**
* @author cbx
* @create 2021/12/20
*/
public class HashTable {
public static void main(String[] args) {
// 创建一个哈希表
HashTab hashTab = new HashTab(7);
//写一个简单的菜单
String key = "";
Scanner scanner = new Scanner(System.in);
while(true) {
System.out.println("add: 添加雇员");
System.out.println("list: 显示雇员");
System.out.println("find: 查找雇员");
System.out.println("exit: 退出系统");
key = scanner.next();
switch (key) {
case "add":
System.out.println("输入 id");
int id = scanner.nextInt();
System.out.println("输入名字");
String name = scanner.next();
//创建 雇员
Emp emp = new Emp(id, name);
hashTab.add(emp);
break;
case "list":
hashTab.list();
break;
case "find":
System.out.println("请输入要查找的 id");
id = scanner.nextInt();
hashTab.findEmpById(id);
break;
case "exit":
scanner.close();
System.exit(0);
default:
break;
}
}
}
}
// 定义hash表
class HashTab{
public EmployLinkedList[] employLinkedListArray;
private int size; //有多少条链表
public HashTab(int size) {
// 初始化链表
this.size = size;
this.employLinkedListArray = new EmployLinkedList[size];
// 不要忘了 分别初始化每个链表
for (int i = 0; i < size; i++){
employLinkedListArray[i] = new EmployLinkedList();
}
}
// 添加顾员
public void add (Emp emp){
// 通过员工的Id 得到该员工应该添加到哪一个链表
int empLinkedListNo = hashFun(emp.id);
// 将emp 添加到链表自己中
employLinkedListArray[empLinkedListNo].add(emp);
}
//遍历所有的链表
public void list(){
int index = 0;
for (EmployLinkedList e :employLinkedListArray){
e.list(index);
index++;
}
}
// 添加顾员
public void findEmpById(int id){
int empLinkedListNo = hashFun(id);
System.out.println(employLinkedListArray[empLinkedListNo].findEmpById(id)==null?"没有该节点哦":
employLinkedListArray[empLinkedListNo].findEmpById(id));
}
// 编写一个散列函数 使用简单的取模法
public int hashFun(int id){
return id % size;
}
}
// 表示顾员
class Emp{
public int id;
public String name;
public Emp next = null;
public Emp(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "Emp{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
// 创建一个EmployLinkedList
class EmployLinkedList{
// 头指针 指向第一个Emp ,这个头指针是直接指向第一个Emp
private Emp head = null;
// 添加顾员到链表
// 假定添加顾员的时候 id自增 将该雇员插入链表的最后一个
public void add(Emp emp){
if (head == null){
head = emp;
return;
}
Emp temp = head;
while (temp.next != null){
temp = temp.next;
}
// 当前的temp为最后一个
temp.next = emp;
}
// 遍历连表的顾员信息
public void list(int i){
if (head == null){
System.out.println("第"+i+"条链表为空");
System.out.println();
return;
}
Emp temp = head;
System.out.print("第"+i+"条链表内的数据为: ");
while (temp != null){
System.out.print(temp+" ");
temp = temp.next;
}
System.out.println();
}
// 根据Id查找顾员
// 如过找不到返回空
public Emp findEmpById(int id) {
if (head == null){
return null;
}
Emp temp = head;
while (temp != null){
if (temp.id == id){
return temp;
}
temp = temp.next;
}
return temp;
}
}
二叉树
对数组 链表 树的比较



二叉树的概念

前中后序遍历图解

前中后序遍历实例

代码实现
package com.cbx.tree;
/**
* @author cbx
* @date 2021/12/24
* @apiNote
*/
public class BinaryTreeDemo {
public static void main(String[] args) {
// 先创建一个二叉树
BinaryTree binaryTree = new BinaryTree();
// 创建需要的节点
HeroNode root = new HeroNode(1,"松江");
HeroNode node2 = new HeroNode(2,"无用");
HeroNode node3 = new HeroNode(3,"卢俊义");
HeroNode node4 = new HeroNode(4,"林冲");
root.setLeft(node2);
root.setRight(node3);
node3.setRight(node4);
binaryTree.setRoot(root);
System.out.println("前序遍历");
binaryTree.preOrder();
System.out.println("中序遍历");
binaryTree.infixOrder();
System.out.println("后序遍历");
binaryTree.postOrder();
}
}
// 定义BinaryTree 二叉树
class BinaryTree{
private HeroNode root;
public void setRoot(HeroNode root) {
this.root = root;
}
// 前序遍历
public void preOrder(){
if (this.root != null){
this.root.preOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
// 中序遍历
public void infixOrder(){
if (this.root != null){
this.root.infixOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
// 后序遍历
public void postOrder(){
if (this.root != null){
this.root.postOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
}
// 先创建HeroNode 节点
class HeroNode {
private int no;
private String name;
private HeroNode left;// 默认null
private HeroNode right;// 默认null
public HeroNode(int no,String name){
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
// 编写前序遍历的方法
public void preOrder(){
System.out.println(this); // 先输出父节点
// 递归向左子树前序遍历
if (this.left != null){
this.left.preOrder();
}
// 递归向右子树前序遍历
if (this.right != null){
this.right.preOrder();
}
}
// 中序遍历
public void infixOrder(){
// 递归向左子树中序遍历
if (this.left != null){
this.left.infixOrder();
}
// 输出父节点
System.out.println(this);
// 递归向右子树中遍历
if (this.right != null){
this.right.infixOrder();
}
}
// 后序遍历
public void postOrder(){
if (this.left != null){
this.left.postOrder();
}
if (this.right != null){
this.right.postOrder();
}
System.out.println(this);//输出父节点
}
}
前中后序查找实例

package com.cbx.tree;
/**
* @author cbx
* @date 2021/12/24
* @apiNote
*/
public class BinaryTreeDemo {
public static void main(String[] args) {
// 先创建一个二叉树
BinaryTree binaryTree = new BinaryTree();
// 创建需要的节点
HeroNode root = new HeroNode(1,"松江");
HeroNode node2 = new HeroNode(2,"无用");
HeroNode node3 = new HeroNode(3,"卢俊义");
HeroNode node4 = new HeroNode(4,"林冲");
HeroNode node5 = new HeroNode(5,"关胜");
root.setLeft(node2);
root.setRight(node3);
node3.setRight(node4);
node3.setLeft(node5);
binaryTree.setRoot(root);
System.out.println("前序遍历");
binaryTree.preOrder();
System.out.println("中序遍历");
binaryTree.infixOrder();
System.out.println("后序遍历");
binaryTree.postOrder();
// 前序遍历查找
// 前序遍历的此时
// 比较了4次
System.out.println("前序遍历查找");
HeroNode heroNode = binaryTree.preOrderSearch(5);
if (heroNode != null){
System.out.println("找到该节点 :"+heroNode.toString());
}else {
System.out.println("没有该英雄哦");
}
// 中序遍历查找
// 比较了3次
System.out.println("中序遍历查找");
heroNode = binaryTree.infixOrderSearch(5);
if (heroNode != null){
System.out.println("找到该节点 :"+heroNode.toString());
}else {
System.out.println("没有该英雄哦");
}
// 后序遍历查找
// 比较了2次
System.out.println("后序遍历查找");
heroNode = binaryTree.postOrderSearch(5);
if (heroNode != null){
System.out.println("找到该节点 :"+heroNode.toString());
}else {
System.out.println("没有该英雄哦");
}
}
}
// 定义BinaryTree 二叉树
class BinaryTree{
private HeroNode root;
public void setRoot(HeroNode root) {
this.root = root;
}
// 前序遍历
public void preOrder(){
if (this.root != null){
this.root.preOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
// 中序遍历
public void infixOrder(){
if (this.root != null){
this.root.infixOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
// 后序遍历
public void postOrder(){
if (this.root != null){
this.root.postOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
// 前序遍历查找
public HeroNode preOrderSearch(int no){
if (root != null){
return root.preOrderSearch(no);
}else {
return null;
}
}
// 中序遍历查找
public HeroNode infixOrderSearch(int no){
if (root != null){
return root.infixOrderSearch(no);
}else {
return null;
}
}
// 后序遍历查找
public HeroNode postOrderSearch(int no){
if (root != null){
return root.postOrderSearch(no);
}else {
return null;
}
}
}
// 先创建HeroNode 节点
class HeroNode {
private int no;
private String name;
private HeroNode left;// 默认null
private HeroNode right;// 默认null
public HeroNode(int no,String name){
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
// 编写前序遍历的方法
public void preOrder(){
System.out.println(this); // 先输出父节点
// 递归向左子树前序遍历
if (this.left != null){
this.left.preOrder();
}
// 递归向右子树前序遍历
if (this.right != null){
this.right.preOrder();
}
}
// 中序遍历
public void infixOrder(){
// 递归向左子树中序遍历
if (this.left != null){
this.left.infixOrder();
}
// 输出父节点
System.out.println(this);
// 递归向右子树中遍历
if (this.right != null){
this.right.infixOrder();
}
}
// 后序遍历
public void postOrder(){
if (this.left != null){
this.left.postOrder();
}
if (this.right != null){
this.right.postOrder();
}
System.out.println(this);
}
// 前序遍历查找
/**
*
* @param no 查找的节点
* @return 如果找到就返回该node,如果没有找到就返回null
*/
public HeroNode preOrderSearch(int no){
// 比较当前节点是不是
if (this.no == no){
return this;
}
// 1.判断当前节点的左子节点是否为空,如果不为空,则向左递归前序遍历查找
// 2.如果左递归前序查找找到了节点,则返回
HeroNode resNode = null;
if (this.left != null){
resNode = this.left.preOrderSearch(no);
}
if (resNode != null){ // 说明左子树找到
return resNode;
}
// 1.判断当前节点的右子节点是否为空,如果不为空,则向右递归前序遍历查找
// 2.如果右递归前序查找找到了节点,则返回
if (this.right != null){
resNode = this.right.preOrderSearch(no);
}
return resNode;
}
// 中序遍历查找
public HeroNode infixOrderSearch(int no){
// 判断当前节点的左子节点是否为空,如果不为空,则递归中序查找
HeroNode resNode = null;
if (this.left != null){
resNode = this.left.infixOrderSearch(no);
}
if (resNode != null){
return resNode;
}
// 如果找到,则返回,如果没有找到,就和当前的节点比较,如果是则返回当前节点
if (this.no == no){
return this;
}
// 否则继续进行右递归的中序查找
if (this.right != null){
resNode = this.right.infixOrderSearch(no);
}
return resNode;
}
// 后序遍历查找
public HeroNode postOrderSearch(int no){
// 判断当前节点的左子节点是否为空,如果不为空,则向左递归后序遍历查找
HeroNode resNode = null;
if (this.left != null){
resNode = this.left.postOrderSearch(no);
}
if (resNode != null){
return resNode;
}
// 如果左子树没有找到,则向右子树递归进行后序遍历查找
if (this.right != null){
resNode = this.right.postOrderSearch(no);
}
if (resNode != null){
return resNode;
}
// 如果左右子树都没有找到,就比较当前节点是不是
if (this.no == no){
return this;
}
return resNode;
}
}
二叉树的删除


// 递归删除节点
// 1 如果删除的节点是叶子节点 ,则删除该节点
// 2 如果是非叶子节点 则删除该子树
public void delete(int no){
if (this.left != null && this.left.no == no){
this.left = null;
return;
}
if (this.right != null && this.right.no == no){
this.right = null;
return;
}
if (this.left != null){
this.left.delete(no);
}
if (this.right != null){
this.right.delete(no);
}
}
// 调用删除的方法
public void delete(int no) {
//考虑如果是空树则提示数位空
if (this.root == null) {
System.out.println("root为null,无法删除");
} else {
// 如果该树根节点就是要删除的树 直接将数变为空树
if (this.root.getNo() == no) {
root = null;
} else {
root.delete(no);
}
}
}
// 测试删除
System.out.println("删除前");
binaryTree.preOrder();
binaryTree.delete(3);
System.out.println("删除后");
binaryTree.preOrder();
顺序存储二叉树

代码实现(前序中序后序遍历)
需求: 给你一个数组 {1,2,3,4,5,6,7},要求以二叉树前序中序后序遍历的方式进行遍历。 前序遍历的结果应当为 1,2,4,5,3,6,7
中序遍历的结果应当为 4,2,5,1,6,3,7
后序遍历的结果应当为 4,5,2,6,7,3,1
package com.cbx.tree;
/**
* @author cbx
* @date 2021/12/25
* @apiNote
*/
public class ArrayBinaryTreeDemo {
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7};
// 创建一个ArrayBinaryTree
ArrayBinaryTree arrayBinaryTree = new ArrayBinaryTree(arr);
System.out.println("顺序存储二叉树的前序遍历为");
arrayBinaryTree.preOrder();
System.out.println();
System.out.println("顺序存储二叉树的中序遍历为");
arrayBinaryTree.infixOrder();
System.out.println();
System.out.println("顺序存储二叉树的后序遍历为");
arrayBinaryTree.postOrder();
}
}
// 编写一个ArrayBinaryTree , 实现顺序存储二叉树遍历
class ArrayBinaryTree {
private int[] arr;// 存储数据节点的数据
public ArrayBinaryTree(int[] arr){
this.arr = arr;
}
public void preOrder(){
this.preOrder(0);
}
public void infixOrder(){
this.infixOrder(0);
}
public void postOrder(){
this.postOrder(0);
}
// 编写一个方法 完成顺序存储二叉树的前序遍历
public void preOrder(int index){ // index 表示数组的下标
// 如果数组为空 或者 arr.length = 0
if (arr == null || arr.length == 0){
System.out.println("数组为空,不能按照二叉树的前序遍历");
return;
}
// 输出当前的元素
System.out.printf("%d\t",arr[index]);
// 向左递归遍历,第n个元素的左节点为2*n+1
if (2*index+1<arr.length){
preOrder(2*index+1);
}
// 向右递归遍历,第n个元素的左节点为2*n+2
if (2*index+2<arr.length){
preOrder(2*index+2);
}
}
// 编写一个方法 完成顺序存储二叉树的中序遍历
public void infixOrder(int index){ // index 表示数组的下标
// 如果数组为空 或者 arr.length = 0
if (arr == null || arr.length == 0){
System.out.println("数组为空,不能按照二叉树的中序遍历");
return;
}
// 向左递归遍历,第n个元素的左节点为2*n+1
if (2*index+1<arr.length){
infixOrder(2*index+1);
}
// 输出当前的元素
System.out.printf("%d\t",arr[index]);
// 向右递归遍历,第n个元素的左节点为2*n+2
if (2*index+2<arr.length){
infixOrder(2*index+2);
}
}
// 编写一个方法 完成顺序存储二叉树的后序遍历
public void postOrder(int index){ // index 表示数组的下标
// 如果数组为空 或者 arr.length = 0
if (arr == null || arr.length == 0){
System.out.println("数组为空,不能按照二叉树的后序遍历");
return;
}
// 向左递归遍历,第n个元素的左节点为2*n+1
if (2*index+1<arr.length){
postOrder(2*index+1);
}
// 向右递归遍历,第n个元素的左节点为2*n+2
if (2*index+2<arr.length){
postOrder(2*index+2);
}
// 输出当前的元素
System.out.printf("%d\t",arr[index]);
}
}

线索化二叉树




代码实现 (中序线索化)
package com.cbx.tree.threadedbinarytree;
/**
* @author cbx
* @date 2021/12/26
* @apiNote
*/
public class ThreadedBinaryTreeDemo {
public static void main(String[] args) {
HeroNode1 root = new HeroNode1(1, "tom");
HeroNode1 node1 = new HeroNode1(3, "jack");
HeroNode1 node2 = new HeroNode1(6, "luyi");
HeroNode1 node3 = new HeroNode1(8, "mary");
HeroNode1 node4 = new HeroNode1(10, "ll");
HeroNode1 node5 = new HeroNode1(14, "dim");
// 二叉树 后面递归创建 现在手动创建
root.setLeft(node1);
root.setRight(node2);
node1.setLeft(node3);
node1.setRight(node4);
node2.setLeft(node5);
// 测试线索化
ThreadedBinaryTree threadedBinaryTree = new ThreadedBinaryTree();
threadedBinaryTree.setRoot(root);
threadedBinaryTree.threadedNodes();
// 以node4 10号 节点做测试
HeroNode1 leftNode = node4.getLeft();
HeroNode1 rightNode = node4.getRight();
// 没有线索化之前 leftNode = rightNode = null;
System.out.println("10号节点的前驱节点为 "+leftNode);// 10号节点的前驱节点为 HeroNode1{no=3, name='jack'}
System.out.println("10号节点的后继节点为 "+rightNode);// 10号节点的后继节点为 HeroNode1{no=1, name='tom'}
}
}
// 定义一个线索二叉树 ThreadedBinaryTree
class ThreadedBinaryTree {
private HeroNode1 root;
// 为了实现线索化 需要创建一个指向当前节点的前驱节点的指针
// pre在递归进行线索化时 总是指向前一个节点
private HeroNode1 pre = null;
public void setRoot(HeroNode1 root) {
this.root = root;
}
public void threadedNodes() {
this.threadedNodes(root);
}
/**
* 编写 对二叉树 进行中序线索化的方法
* @param node 当前需要线索化的节点
*/
public void threadedNodes(HeroNode1 node){
//如果 node = null 不能线索化
if(node == null) {
return;
}
//(1) 线索化左子树
if (node.getLeft() != null) {
threadedNodes(node.getLeft());
}
//(2) 线索化当前节点
// 先处理当前节点的前驱节点
if (node.getLeft() == null){
node.setLeftType(1);
node.setLeft(pre);
}
// 处理后继后继节点
if (pre != null && pre.getRight() == null){
pre.setRight(node);
pre.setRightType(1);
}
// 很重要 每次处理完当前节点后 让这个节点变成下一个节点的前驱节点
pre = node;
//(3) 线索化右子树
if (node.getRight() != null) {
threadedNodes(node.getRight());
}
}
// 前序遍历
public void preOrder(){
if(this.root != null){
root.preOrder();
}else {
System.out.println("二叉树为空 无法遍历");
}
}
// 中序遍历
public void infixOrder(){
if(this.root != null){
root.infixOrder();
}else {
System.out.println("二叉树为空 无法遍历");
}
}
// 前序遍历
public void postOrder(){
if(this.root != null){
root.postOrder();
}else {
System.out.println("二叉树为空 无法遍历");
}
}
// 前序遍历查找
public HeroNode1 preOrderSearch(int no){
if (root != null){
return root.preOrderSearch(no);
}else return null;
}
// 中序序遍历查找
public HeroNode1 infixOrderSearch(int no){
if (root != null){
return root.infixOrderSearch(no);
}else return null;
}
// 后序序遍历查找
public HeroNode1 postOrderSearch(int no){
if (root != null){
return root.postOrderSearch(no);
}else return null;
}
public void delete(int no){
//考虑如果是空树则提示数位空
if (this.root == null){
System.out.println("root为null,无法删除");
}else {
// 如果该树根节点就是要删除的树 直接将数变为空树
if (this.root.getNo() == no){
root = null;
}else {
root.delete(no);
}
}
}
}
// 创建HeroNode1
class HeroNode1 {
private int no;
private String name;
private HeroNode1 left; // 左子树
private HeroNode1 right; // 右子树
// 说明
// leftType = 0 表示指向左子树 leftType = 1 表示指向前驱节点
// rightType = 0 表示指向右子树 rightType = 1 表示指向后继节点
private int leftType;
private int rightType;
@Override
public String toString() {
return "HeroNode1{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
public HeroNode1(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode1 getLeft() {
return left;
}
public void setLeft(HeroNode1 left) {
this.left = left;
}
public HeroNode1 getRight() {
return right;
}
public void setRight(HeroNode1 right) {
this.right = right;
}
public int getLeftType() {
return leftType;
}
public void setLeftType(int leftType) {
this.leftType = leftType;
}
public int getRightType() {
return rightType;
}
public void setRightType(int rightType) {
this.rightType = rightType;
}
// 前序遍历的方法
public void preOrder() {
System.out.println(this); //先输出父节点
// 递归遍历左子树
if (this.left != null) {
this.left.preOrder();
}
// 递归遍历右子树
if (this.right != null) {
this.right.preOrder();
}
}
// 中序遍历的方法
public void infixOrder() {
// 递归遍历左子树
if (this.left != null) {
this.left.infixOrder();
}
System.out.println(this); //输出父节点
// 递归遍历右子树
if (this.right != null) {
this.right.infixOrder();
}
}
// 后序遍历的方法
public void postOrder() {
// 递归遍历左子树
if (this.left != null) {
this.left.postOrder();
}
// 递归遍历右子树
if (this.right != null) {
this.right.postOrder();
}
System.out.println(this); //输出父节点
}
/**
* 前序查找的方法
*
* @param no
* @return 找到返回节点 没有找到返回no
*/
public HeroNode1 preOrderSearch(int no) {
System.out.println("进入前序遍历查找");
// 先比较当前节点
if (this.no == no) {
return this;
}
HeroNode1 resNode = null;
if (this.left != null) {
resNode = this.left.preOrderSearch(no);
}
if (resNode != null) {
return resNode;
}
// 递归遍历右子树
if (this.right != null) {
resNode = this.right.preOrderSearch(no);
}
return resNode;
}
/**
* 中序查找的方法
*
* @param no
* @return 找到返回节点 没有找到返回no
*/
public HeroNode1 infixOrderSearch(int no) {
HeroNode1 resNode = null;
if (this.left != null) {
resNode = this.left.infixOrderSearch(no);
}
if (resNode != null) {
return resNode;
}
System.out.println("进入中序遍历查找");
// 比较当前节点
if (this.no == no) {
return this;
}
// 递归遍历右子树
if (this.right != null) {
resNode = this.right.infixOrderSearch(no);
}
return resNode;
}
/**
* 后序查找的方法
*
* @param no
* @return 找到返回节点 没有找到返回no
*/
public HeroNode1 postOrderSearch(int no) {
HeroNode1 resNode = null;
if (this.left != null) {
resNode = this.left.postOrderSearch(no);
}
if (resNode != null) {
return resNode;
}
// 递归遍历右子树
if (this.right != null) {
resNode = this.right.postOrderSearch(no);
}
if (resNode != null) {
return resNode;
}
System.out.println("进入后序遍历查找");
// 比较当前节点
if (this.no == no) {
return this;
}
return resNode;
}
// 递归删除节点
// 1 如果删除的节点是叶子节点 ,则删除该节点
// 2 如果是非叶子节点 则删除该子树
public void delete(int no) {
if (this.left != null && this.left.no == no) {
this.left = null;
return;
}
if (this.right != null && this.right.no == no) {
this.right = null;
return;
}
if (this.left != null) {
this.left.delete(no);
}
if (this.right != null) {
this.right.delete(no);
}
}
}
遍历线索化二叉树

class ThreadedBinaryTree :
// 遍历线索化二叉树的方法
public void threadedList(){
// 定义一个变量 存储当前遍历的节点 从root开始
HeroNode1 node = root;
while (node != null){
// 循环找到 第一个 leftType = 1的节点 当前例子应该是8
// 后面随着遍历 而变化 当 leftType == 1时 说明该节点是按照线索化处理后的有效节点
while (node.getLeftType() == 0){
node = node.getLeft();
}
System.out.println(node);
// 如果当前节点的右指针指向的是后驱节点,则直接输出后驱节点
while (node.getRightType() == 1){
// 获取当前节点的后驱节点
node = node.getRight();
System.out.println(node);
}
// 循环结束,当前node.getRightType()!=1,替换遍历的节点
node = node.getRight();
}
}
main:
// 当线索化二叉树后 无法使用原来的遍历方法
System.out.println("线索化的遍历方式");
threadedBinaryTree.threadedList();
树结构的实际应用







代码实现
我的理解:上图的数组变为无序树 再去找最后一个叶子节点i , i–循环到i =0 将当前无序树变成 一个大顶锥 把返回的数组的第一个元素(当前最大的数了)和最后一个元素交换 ,再把交换后的最大的数的之前的数据当做一个新数组 从根节点开始(上面的"最后一个叶子节点" 变成从根节点开始 因为下面已经都是堆排序的数组了 只需考虑根节点) 执行上面的生成大顶锥再交换的步骤 直到数组(“再把交换后的最大的数的之前的数据当做一个新数组”) 为空
package com.cbx.tree;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/1
* @apiNote
*/
public class HeapSort {
public static void main(String[] args) {
// 数组升序排序
int arr[] = {4, 6, 8, 5, 9};
heapSort(arr);
}
// 编写一个堆排序的方法
public static void heapSort(int[] arr) {
/*System.out.println(" 将数组 变成大顶堆");
System.out.println();
// 将数组 变成大顶堆
// 分布完成
System.out.println(" 将数组 变成一个大顶堆 分布完成");
adjustHeap(arr,1, arr.length);
System.out.println("第一轮" + Arrays.toString(arr));
adjustHeap(arr,0, arr.length);
System.out.println("第二轮" + Arrays.toString(arr));
*//**
* 堆排序
* 第一轮[4, 9, 8, 5, 6]
* 第二轮[9, 6, 8, 5, 4]
*/
System.out.println();
System.out.println(" 将数组(无序树) 变成一个大顶堆 一次完成");
// 最后一叶子节点 = arr.length/2 - 1
for (int i = arr.length / 2 - 1; i >= 0; i--) {
adjustHeap(arr, i, arr.length);
}
System.out.println(Arrays.toString(arr));
System.out.println("");
// 将根节点(最大的数) 放到数组的最后位置 然后 将该数以前的数组再次构建成大顶锥 再交换 .... 再.. 在交换
int temp = 0;
for (int j = arr.length - 1; j > 0; j--) {
// 交换
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, j);
}
System.out.println("排序结果:" + Arrays.toString(arr));
}
/**
* 将无序数组(对应的二叉树) 调整成一个大顶堆
* 完成将以 i 对应的非叶子节点的树 调整大顶堆 {4,6,8,5,9} => i=1时 {4,9,8,5,6}
* 第二次 传入的是 i = 0 => {9,6,8,5,4}
*
* @param arr 待调整的数组
* @param i 表示非叶子节点的索引
* @param length 对多少个元素进行调整
*/
public static void adjustHeap(int[] arr, int i, int length) {
int temp = arr[i];//先取出当前元素的值, 保存在临时变量
// 开始调整
// k = i * 2 + 1 指向 i的左子几节点 下一个 k = k * 2 +1 指向当前节点的左子节点(i的左子节点的下一个左子节点)
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if (k + 1 < length && arr[k] < arr[k + 1]) {// 说明左子节点的值 小于右子节点的值
k++;// k指向右子节点
}
if (arr[k] > temp) {// 如果子节点大于父节点
arr[i] = arr[k];
i = k;// 把较大的值 付给当前节点 然后 i指向k 继续循环比较
} else {
break;
}
}
//for循环结束后 将 以 i 为父节点的树 的最大值 放到了最顶上(局部)
arr[i] = temp;// 将temp放在调整后的位置
}
}
堆排序的时间复杂度为O(nlogn) 8w 随机数的排序 秒杀 80w依旧秒杀 800w 4秒
哈夫曼树




哈夫曼树的代码实现
package com.luyi.huffman;
import java.util.ArrayList;
import java.util.Collections;
/**
* @author cbx
* @date 2022/1/2
* @apiNote
*/
public class HuffmanTree {
public static void main(String[] args) {
int[] arr = {13,7,8,3,29,6,1};
System.out.println("前序遍历");
preOrder(createHuffmanTree(arr));
System.out.println();
/**
* 前序遍历
* 67 29 38 15 7 8 23 10 4 1 3 6 13
*/
}
// 创建 哈夫曼树的方法
public static Node createHuffmanTree(int[] arr){
// 第一步 为了操作方便 遍历arr数组 将arr的元素 构建成一个Node 将Node放入ArrayList
ArrayList<Node> nodes = new ArrayList<>();
for(int value : arr){
nodes.add(new Node(value));
}
// 排序 从小到大
Collections.sort(nodes);
while (nodes.size() >1) {
// 第二步 取出根节点权值最小的两颗二叉树(一个节点也是一颗二叉树)
Node left = nodes.get(0);
Node right = nodes.get(1);
// 构建一颗新的二叉树
Node parent = new Node(left.value + right.value);
parent.left = left;
parent.right = right;
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
Collections.sort(nodes);
}
return nodes.get(0);
}
// 写一个前序遍历
public static void preOrder(Node node){
if (node == null){
System.out.println("该树为空 无法遍历");
return;
}
System.out.print(node.value+" ");
if(node.left != null){
preOrder(node.left);
}
if(node.right != null){
preOrder(node.right);
}
}
}
// 创建节点类
// 为了让Node 支持Collections集合排序 让Node实现Comparable结构
class Node implements Comparable<Node>{
int value; // 节点权值
Node left; // 指向左子节点
Node right; // 指向右子节点
public Node(int value) {
this.value = value;
}
@Override
public String toString() {
return "Node{" +
"value=" + value +
'}';
}
@Override
public int compareTo(Node o) {
// 从小到大的排序
// 从大到小 -(this.value - o.value)
return this.value - o.value;
}
}
哈夫曼编码






代码实现

最佳实践-数据压缩(创建赫夫曼树)

最佳实践-数据压缩(生成赫夫曼编码和赫夫曼编码后的数据)

最佳实践-数据解压(使用赫夫曼编码解码)

代码实现 (个人觉得面试真的用不到,)
package com.luyi.huffmancdoe;
import com.sun.beans.editors.ByteEditor;
import org.omg.CosNaming.IstringHelper;
import sun.security.util.Length;
import java.util.*;
/**
* @author cbx
* @date 2022/1/3
* @apiNote
*/
public class HuffmanCode {
public static void main(String[] args) {
String str = "i like like like java do you like a java"; // 长度是40
byte[] bytes = str.getBytes();
List<Node> nodes = getNode(bytes);
Node huffmanTree = createHuffmanTree(nodes);
huffmanTree.preOrder();
// getCodes(huffmanTree,"" , stringBuilder);
Map<Byte, String> codes = getCodes(huffmanTree);
System.out.println("生成的哈夫曼编码表:" + codes);
// 测试
byte[] zip = zip(bytes, codes);
System.out.println("哈夫曼编码压缩过后的bytes "+ Arrays.toString(zip)); // 长度是17
// 封装类的测试
System.out.println("封装类的测试");
byte[] huffmanZip = huffmanZip(bytes);
System.out.println("哈夫曼编码压缩过后的bytes "+ Arrays.toString(huffmanZip));
// 解码测试
byte[] source = decode(huffmanCode, huffmanZip);
System.out.println("原来的字符串 "+new String(source));
}
/**
* 编写一个方法将字符串对应的byte[]数组 通过生成的哈夫曼编码表 返回一个哈夫曼编码 压缩后的byte数组
* @param bytes 原始的字符串对应的byte[]数组
* @param huffmanCode 生成得Huffman编码
* @return 返回哈夫曼树编码处理后的byte[]
* 当前例子将会返回(类似 因为生成得Huffman树的结构不同 但是长度会相同)1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000
* 101111111100110001001010011011100
* =>对应的byte[] 数组 放入 8个数字 对应一个byte 放入数组 例如
* 10101000(补码) => byte (10101000 => 10101000 -1 => 10100111(反码) => 11011000(源码) =>-88)
*/
private static byte[] zip(byte[] bytes, Map<Byte,String> huffmanCode){
// 1 先用Huffman编码表 将bytes 转成 Huffman编码对应的字符串
StringBuilder stringBuilder = new StringBuilder();
// 遍历byte数组
for(byte b : bytes){
stringBuilder.append(huffmanCode.get(b));
}
System.out.println(stringBuilder.toString());
// 2 将01010001011111....转为一个byte数组
// 如果被8乘除 就是stringBuilder.length()/8 没有没整除就是 (stringBuilder.length()+1)/8
int num = (stringBuilder.length()+7) / 8;
// 创建 一个存储压缩后的byte数组
byte[] huffmanCodeBytes = new byte[num];
int index = 0; // 第几个byte
for (int i = 0; i < stringBuilder.length(); i+=8){// 步长为8
String strByte;
if(i + 8 > stringBuilder.length()) {// 不够8位
strByte = stringBuilder.substring(i); // i-结束
}else {
strByte = stringBuilder.substring(i, i + 8);
}
huffmanCodeBytes[index++] = (byte) Integer.parseInt(strByte,2); // 二进制
}
return huffmanCodeBytes;
}
// 使用一个方法 将前面的方法封装起来 ,便于调用
/**
* @param bytes 原始的字符串对应的字节数组
* @return 返回的是经过哈夫曼编码处理后(压缩后)的数组
*/
private static byte[] huffmanZip(byte[] bytes) {
List<Node> nodes = getNode(bytes);
// 创建哈夫曼树
Node huffmanTreeRoot = createHuffmanTree(nodes);
// 根据哈夫曼树生成对应的哈夫曼编码
Map<Byte, String> huffmanCodes = getCodes(huffmanTreeRoot);
// 根据生成的哈夫曼编码 对原来的数据进行封装 得到压缩后的哈夫曼树的编码
byte[] zip = zip(bytes, huffmanCodes);
return zip;
}
// 完成数据的解压
// 思路
// 1 将huffmanCodeBytes [40, 46, -56, 46, -56, 46, -55, 5, -123, 6, -88, -46, -126, -20, -124, -126, 24 ]
// 重新转成赫夫曼编码对应的字符串 100100100...
// 2 将赫夫曼对应的二进制字符串 100100100... 对照 哈夫曼编码转成 i like java......
/**
* 将byte 转成一个二进制的字符串
* @param flag 标志当前是否需要补高位 如果是true 需要补高位
* @param b 传入的byte
* @return 返回 b 对应二进制的字符串(补码返回)
*/
private static String byteToBitString(boolean flag,byte b){
int temp = b; // 向上强转 b变成int
// 如果是整数 需要补高位
if(flag) { // 如果当前长度 没有8位 不用高位补码
temp |= 256; // 按位与 256 =1 0000 0000 1 = 0000 0001 => 1 0000 0001
}
String str = Integer.toBinaryString(temp); // 返回temp 对应二进制的补码
if (flag) {
return str.substring(str.length() - 8); // 取最后8位
}else {
return str;
}
}
/**
* 编写有个方法 完成对压缩数据的编码
* @param huffmanCode 哈夫曼编码表
* @param huffmanBytes 哈夫曼编码的得到的字节数组
* @return 原理的字符串对应的数组
*/
private static byte[] decode(Map<Byte,String> huffmanCode, byte[] huffmanBytes){
// 1 先得到 huffmanBytes 的二进制的字符串 形式为"10101010..."
StringBuilder stringBuilder = new StringBuilder();
// 将byte数组转成二进制的字符串
boolean flag = false;
for(int i = 0; i < huffmanBytes.length; i++){
// 判断是不是最后一个字节
if (huffmanBytes.length-1 == i){
flag = true;
}
stringBuilder.append(byteToBitString(!flag,huffmanBytes[i]));
}
// System.out.println("哈弗曼树对应的二进制字符串是 "+stringBuilder.toString());
// 把字符串安装到指定的哈夫曼编码进行解码
// 把哈夫曼树编码进行调换 因为反向查询 a -> 100 100->a
Map<String, Byte> map = new HashMap<>();
for (Map.Entry<Byte,String> entry : huffmanCode.entrySet()){
map.put(entry.getValue(), entry.getKey());
}
//System.out.println(map);
//创键一个集合 存放byte
List<Byte> list = new ArrayList<>();
// i理解成是一个索引 扫描stringBuilder
for (int i = 0; i < stringBuilder.length();){
int count = 1; // 小的计数器
flag = true;
Byte b = null;
while (flag) {
// 取出一个'1'或'0' 组建key 去map{000=108, 01=32, 001=105, 01000=100, 01011=118...中查找
String key = stringBuilder.substring(i, i + count);// i 不动 让count移动// 直到匹配到一个字符
b = map.get(key);
if (b == null) {
count++;
} else {
//匹配到了
flag = false;
}
}
list.add(b); i += count;
}
// for循环结束后 list就存放了所有字符
// 把list中的数据放入byte数组中
byte[] b = new byte[list.size()];
for (int i = 0; i < b.length; i++){
b[i] = list.get(i);
}
return b;
}
/**
* 构建字节Node数组
* @param bytes 字节数组
* @return 返回node数组
*/
public static List<Node> getNode(byte[] bytes){
// 创建一个arrayList
ArrayList<Node> nodes = new ArrayList<>();
// 存储每一个byte出现的次数 map来做
HashMap<Byte, Integer> map = new HashMap<Byte, Integer>();
for (byte b : bytes){
Integer count = map.get(b);
if (count == null){
map.put(b, 1);
}else {
map.put(b, ++count);
}
}
// 每个键值对转成node对象 并加入nodes
// 遍历map
for(Map.Entry<Byte,Integer> entry : map.entrySet()){
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
// 构建哈夫曼树
public static Node createHuffmanTree(List<Node> nodes){
if (nodes.size() == 0){
System.out.println("数组为空 无法构建哈夫曼树");
return null;
}
Collections.sort(nodes);
while (nodes.size() > 1){
Collections.sort(nodes);
Node left = nodes.get(0);
Node right = nodes.get(1);
Node node = new Node(null,left.weight + right.weight);
node.left = left;
node.right = right;
nodes.remove(left);
nodes.remove(right);
nodes.add(node);
}
return nodes.get(0);
}
// 生成哈夫曼对应的哈夫曼编码
// 1 将哈夫曼树放在Map<Byte,String> 形式大概为 a->100 d->11000 u->11001 e->1110 v->11011 i->101 y->11010 j->0010 k->1111 l->000 o->0011
// 2 在生成哈夫曼编码表时 需要拼接路径 定义一个stringBuilder 存储某个叶子节点的路径
static Map<Byte,String> huffmanCode = new HashMap<>();
static StringBuilder stringBuilder = new StringBuilder();
// 为了调用方便 重载getCodes
private static Map<Byte, String> getCodes(Node root) {
if (root == null){
return null;
}
// 处理root的左子树
getCodes(root.left, "0", stringBuilder);
getCodes(root.right, "1", stringBuilder);
return huffmanCode;
}
/**
* 将传入的node节点的所有叶子节点的哈夫曼编码得到 , 并放入到HuffmanCodes集合中
* @param node 传入节点 默认根节点
* @param code 路径 左子节点为 0 右子节点为 1
* @param stringBuilder 拼接路径
*/
private static void getCodes(Node node, String code, StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
stringBuilder2.append(code);
if (node != null){
if (node.data == null){ // 非叶子节点
getCodes(node.left,"0",stringBuilder2);
getCodes(node.right,"1",stringBuilder2);
}else {
huffmanCode.put(node.data, stringBuilder2.toString());
}
}
}
}
// 创建node ,带数据和权值
class Node implements Comparable<Node>{
Byte data; // 存放数据本身 比如'a' => 97 ' '=> 32
int weight; // 权值 表示数据(字符) 出现的次数
Node left;
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
// weight 升序排列
return this.weight - o.weight;
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
", weight=" + weight +
'}';
}
// 前序遍历
public void preOrder(){
System.out.println(this);
if(this.left != null){
this.left.preOrder();
}
if(this.right != null){
this.right.preOrder();
}
}
}
最佳实践-文件压缩

/**
* 编写一个方法 对文件进行压缩
* @param srcFile 传入文件的路径
* @param dsFile 压缩后的文件的存储位置
*/
public static void zipFile(String srcFile, String dsFile) {
// 创建输入输出流
// 创建文件的输入流
FileInputStream is = null;
OutputStream os = null;
ObjectOutputStream oos = null;
try {
is = new FileInputStream(srcFile);
// 创建和源文件大小一样的数组byte[]
byte[] b = new byte[is.available()];
is.read(b);
// 获取到文件对应的哈夫曼编码
// 对源文件进行压缩
byte[] huffmanBytes = huffmanZip(b);
// 创建文件的输出流
os = new FileOutputStream(dsFile);
// 创建一个文件输出关联的ObjectOutputStream
oos = new ObjectOutputStream(os);
// 这里以对象流的方式写入哈夫曼编码后的字节数组
oos.write(huffmanBytes); // 先把huffmanBytes写入
// 写入哈夫曼编码 用于数据的恢复 为了以后恢复源文件后使用
oos.writeObject(huffmanCode);
}catch (Exception e){
e.printStackTrace();
}finally {
try {
is.close();
os.close();
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
最佳实践-文件解压(文件恢复)
//编写一个方法,完成对压缩文件的解压
/**
*
* @param zipFile 准备解压的文件
* @param dstFile 将文件解压到哪个路径
*/
public static void unZipFile(String zipFile, String dstFile) {
//定义文件输入流
InputStream is = null;
//定义一个对象输入流
ObjectInputStream ois = null;
//定义文件的输出流
OutputStream os = null;
try {
//创建文件输入流
is = new FileInputStream(zipFile);
//创建一个和 is 关联的对象输入流
ois = new ObjectInputStream(is);
//读取 byte 数组 huffmanBytes
byte[] huffmanBytes = (byte[])ois.readObject();
//读取赫夫曼编码表
Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();
//解码
byte[] bytes = decode(huffmanCodes, huffmanBytes);
//将 bytes 数组写入到目标文件
os = new FileOutputStream(dstFile);
//写数据到 dstFile 文件
os.write(bytes);
} catch (Exception e) {
// TODO: handle exception
System.out.println(e.getMessage());
} finally {
try {
os.close();
ois.close();
is.close();
} catch (Exception e2) {
// TODO: handle exception
System.out.println(e2.getMessage());
}
}
}
哈夫曼编码的注意事项


二叉排序树


二叉排序树的创建和遍历

代码实现
package com.cbx.binarysorttree;
/**
* @author cbx
* @date 2022/1/5
* @apiNote
*/
public class BinarySortTreeDemo {
public static void main(String[] args) {
int[] arr = {7, 3, 10, 12, 5, 1, 9};
BinarySortTree binarySortTree = new BinarySortTree();
for (int a : arr) {
binarySortTree.add(new Node(a));
}
binarySortTree.getRoot().infixOrder();
}
}
// 创建二叉排序树
class BinarySortTree{
private Node root;
public void add(Node node){
if (root == null){
root = node;
}else {
root.add(node);
}
}
public Node getRoot() {
return root;
}
public void setRoot(Node root) {
this.root = root;
}
// 中序遍历
public void infixOrder(){
if (root == null){
System.out.println("当前二叉排序树为空 无法遍历");
}else {
root.infixOrder();
}
}
}
// 创建节点
class Node{
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
public Node() {
}
// 添加节点的方法
// 递归添加节点
public void add(Node node){
if (node == null){
return;
}
if(this.value > node.value){
if (this.left != null){
this.left.add(node);
}else {
this.left = node;
}
}else { // 如果value相等 也走右边节点
if (this.right != null){
this.right.add(node);
}else {
this.right = node;
}
}
}
// 中序遍历
public void infixOrder(){
if(this.left != null){
this.left.infixOrder();
}
System.out.print(this.value+" ");
if (this.right != null){
this.right.infixOrder();
}
}
}
二叉排序树的删除




代码实现
package com.cbx.binarysorttree;
/**
* @author cbx
* @date 2022/1/5
* @apiNote
*/
public class BinarySortTreeDemo {
public static void main(String[] args) {
int[] arr = {7, 3, 10, 12, 5, 1, 9};
BinarySortTree binarySortTree = new BinarySortTree();
for (int a : arr) {
binarySortTree.add(new Node(a));
}
binarySortTree.getRoot().infixOrder();
System.out.println();
// 测试删除
System.out.println("删除节点后");
// 测试删除叶子节点
binarySortTree.delNode(5);
binarySortTree.delNode(7);
binarySortTree.delNode(3);
binarySortTree.delNode(12);
binarySortTree.delNode(9);
// 测试删除 只有一个子节点的节点
binarySortTree.delNode(10);
// 测试删除 只有两个子节点的节点
binarySortTree.delNode(1);
binarySortTree.infixOrder();
}
}
// 创建二叉排序树
class BinarySortTree{
private Node root;
public void add(Node node){
if (root == null){
root = node;
}else {
root.add(node);
}
}
// 删除节点
public void delNode(int value) {
if (root == null){
return;
}else {
// 1 先去找到要删除的节点 targetNode
Node targetNode = search(value);
if (targetNode == null){ //没有找到
return;
}
// 如果这颗二叉树只有一个 targetNode 节点
if (root.left == null && root.right == null){
root = null;
return;
}
// 去找到targetNode的父节点
Node parent = searchParent(value);
// 如果要删除的节点是叶子节点 左节点? 右节点
if (targetNode.left == null && targetNode.right == null){
if (parent.value > value){
parent.left = null;
}else {
parent.right = null;
}
}else if(targetNode.right != null && targetNode.left != null){ // 要删除的节点左右都有子节点
int min = delRightTreeMin(targetNode);
targetNode.value = min;
}else { // 删除只有一颗子树的接单
// 如果要删除的这个节点有左子节点
if (targetNode.left != null){
if (parent != null) {
if (parent.left.value == targetNode.value) {// 如果targetNode是parent的左子节点
parent.left = targetNode.left;
} else {//如果targetNode是parent的右子节点
parent.right = targetNode.left;
}
}else {
root = targetNode.left;
}
}else {
if (parent != null) {
if (parent.left.value == targetNode.value) {// 如果targetNode是parent的左子节点
parent.left = targetNode.right;
} else { //如果targetNode是parent的右子节点
parent.right = targetNode.right;
}
}else {
root = targetNode.right;
}
}
}
}
}
/**
* 找到要删除的节点的右子节点开始的最小节点(右子节点的向左走) 返回该节点的值 删除该节点
* @param node 传入要删除的节点
* @return 返回从要删除的节点的右子节点开始的最小节点(右子节点的向左走)
*/
public int delRightTreeMin(Node node){
Node target = node.right;
while ( target.left != null){
target = target.left;
}
// 删除最小节点
delNode(target.value);
// 返回最小节点的值
return target.value;
}
// 第二种,找到要删除的节点的左子节点开始的最大节点(左子节点的向右走) 返回该节点的值 删除该节点
public int delLeftTreeMax(Node node){
Node target = node.left;
while ( target.right != null){
target = target.right;
}
// 删除最大节点
delNode(target.value);
// 返回最大节点的值
return target.value;
}
// 查找要删除的节点
public Node search(int value){
if (root == null){
return null;
}else {
return root.search(value);
}
}
//查找父节点
public Node searchParent(int value){
if (root == null){
return null;
}else {
return root.searchParent(value);
}
}
public Node getRoot() {
return root;
}
public void setRoot(Node root) {
this.root = root;
}
// 中序遍历
public void infixOrder(){
if (this.getRoot() == null){
System.out.println("当前二叉排序树为空 无法遍历");
}else {
this.getRoot().infixOrder();
}
}
}
// 创建节点
class Node{
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
public Node() {
}
/**
* 查找要删除的节点
* @param value 希望删除的节点
* @return 如果找到返回该节点 否则返回null
*/
public Node search (int value){
if (value == this.value) { // 找到就是该节点
return this;
}else if (value < this.value){
if(this.left != null){
return left.search(value);
}else {
return null;
}
}else {
if(this.right != null){
return this.right.search(value);
}else {
return null;
}
}
}
/**
* 查找要删除节点的父节点
* @param value 希望删除的节点
*/
public Node searchParent(int value){
if (this.left != null && this.left.value == value){
return this;
}else if(this.right != null && this.right.value == value){
return this;
}else {
// 如果查找的值 小于当前节点的值 , 并且当前的节点左子节点不为空
if(value < this.value && this.left != null){
return this.left.searchParent(value);
}else if(value >= this.value && this.right != null){
return this.right.searchParent(value);
}else {
// 真的找不到了 没有父节点
return null;
}
}
}
// 添加节点的方法
// 递归添加节点
public void add(Node node){
if (node == null){
return;
}
if(this.value > node.value){
if (this.left != null){
this.left.add(node);
}else {
this.left = node;
}
}else { // 如果value相等 也走右边节点
if (this.right != null){
this.right.add(node);
}else {
this.right = node;
}
}
}
// 中序遍历
public void infixOrder(){
if(this.left != null){
this.left.infixOrder();
}
System.out.print(this.value+" ");
if (this.right != null){
this.right.infixOrder();
}
}
}
二叉排序树的注意事
如果删除的数10这个根节点 走到这一步时 会报空指针异常 所以需要加一个判断

修改方案如果
parent 判空

// 删除节点
public void delNode(int value) {
if (root == null){
return;
}else {
// 1 先去找到要删除的节点 targetNode
Node targetNode = search(value);
if (targetNode == null){ //没有找到
return;
}
// 如果这颗二叉树只有一个 targetNode 节点
if (root.left == null && root.right == null){
root = null;
return;
}
// 去找到targetNode的父节点
Node parent = searchParent(value);
// 如果要删除的节点是叶子节点 左节点? 右节点
if (targetNode.left == null && targetNode.right == null){
if (parent.value > value){
parent.left = null;
}else {
parent.right = null;
}
}else if(targetNode.right != null && targetNode.left != null){ // 要删除的节点左右都有子节点
int min = delRightTreeMin(targetNode);
targetNode.value = min;
}else { // 删除只有一颗子树的接单
// 如果要删除的这个节点有左子节点
if (targetNode.left != null){
if (parent != null) {
if (parent.left.value == targetNode.value) {// 如果targetNode是parent的左子节点
parent.left = targetNode.left;
} else {//如果targetNode是parent的右子节点
parent.right = targetNode.left;
}
}else {
root = targetNode.left;
}
}else {
if (parent != null) {
if (parent.left.value == targetNode.value) {// 如果targetNode是parent的左子节点
parent.left = targetNode.right;
} else { //如果targetNode是parent的右子节点
parent.right = targetNode.right;
}
}else {
root = targetNode.right;
}
}
}
}
}
平衡二叉树


单旋转 左旋转


package com.cbx.avl;
/**
* @author cbx
* @date 2022/1/8
* @apiNote
*/
public class AVLTreeDemo {
public static void main(String[] args) {
int[] arr = {4,3,6,5,7,8};
AVLTree avlTree = new AVLTree();
for (int ar : arr) {
avlTree.add(new Node(ar));
}
System.out.println("中序遍历");
avlTree.infixOrder();
System.out.println("在平衡处理后");
System.out.println("树的高度="+avlTree.getRoot().height());
System.out.println("树的左子树高度="+avlTree.getRoot().leftHeight());;
System.out.println("树的右子树高度="+avlTree.getRoot().rightHeight());;
}
}
class AVLTree{
private Node root;
public void add(Node node){
if (root == null){
root = node;
}else {
root.add(node);
}
}
// 删除节点
public void delNode(int value) {
if (root == null){
return;
}else {
// 1 先去找到要删除的节点 targetNode
Node targetNode = search(value);
if (targetNode == null){ //没有找到
return;
}
// 如果这颗二叉树只有一个 targetNode 节点
if (root.left == null && root.right == null){
root = null;
return;
}
// 去找到targetNode的父节点
Node parent = searchParent(value);
// 如果要删除的节点是叶子节点 左节点? 右节点
if (targetNode.left == null && targetNode.right == null){
if (parent.value > value){
parent.left = null;
}else {
parent.right = null;
}
}else if(targetNode.right != null && targetNode.left != null){ // 要删除的节点左右都有子节点
int min = delRightTreeMin(targetNode);
targetNode.value = min;
}else { // 删除只有一颗子树的接单
// 如果要删除的这个节点有左子节点
if (targetNode.left != null){
if (parent != null) {
if (parent.left.value == targetNode.value) {// 如果targetNode是parent的左子节点
parent.left = targetNode.left;
} else {//如果targetNode是parent的右子节点
parent.right = targetNode.left;
}
}else {
root = targetNode.left;
}
}else {
if (parent != null) {
if (parent.left.value == targetNode.value) {// 如果targetNode是parent的左子节点
parent.left = targetNode.right;
} else { //如果targetNode是parent的右子节点
parent.right = targetNode.right;
}
}else {
root = targetNode.right;
}
}
}
}
}
/**
* 找到要删除的节点的右子节点开始的最小节点(右子节点的向左走) 返回该节点的值 删除该节点
* @param node 传入要删除的节点
* @return 返回从要删除的节点的右子节点开始的最小节点(右子节点的向左走)
*/
public int delRightTreeMin(Node node){
Node target = node.right;
while ( target.left != null){
target = target.left;
}
// 删除最小节点
delNode(target.value);
// 返回最小节点的值
return target.value;
}
// 第二种,找到要删除的节点的左子节点开始的最大节点(左子节点的向右走) 返回该节点的值 删除该节点
public int delLeftTreeMax(Node node){
Node target = node.left;
while ( target.right != null){
target = target.right;
}
// 删除最大节点
delNode(target.value);
// 返回最大节点的值
return target.value;
}
// 查找要删除的节点
public Node search(int value){
if (root == null){
return null;
}else {
return root.search(value);
}
}
//查找父节点
public Node searchParent(int value){
if (root == null){
return null;
}else {
return root.searchParent(value);
}
}
public Node getRoot() {
return root;
}
public void setRoot(Node root) {
this.root = root;
}
// 中序遍历
public void infixOrder(){
if (this.getRoot() == null){
System.out.println("当前二叉排序树为空 无法遍历");
}else {
this.getRoot().infixOrder();
}
}
}
// 创建节点
class Node{
int value;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
public int leftHeight(){
if (left == null){
return 0;
}
return left.height();
}
public int rightHeight(){
if (right == null){
return 0;
}
return right.height();
}
public int height(){
return Math.max(left == null ? 0 : left.height(), right == null? 0 : right.height())+1;
}
private void leftRotate(){
Node newNode = new Node(value);
newNode.left = left;
newNode.right = right.left;
value = right.value;
right = right.right;
left = newNode;
}
public Node() {
}
/**
* 查找要删除的节点
* @param value 希望删除的节点
* @return 如果找到返回该节点 否则返回null
*/
public Node search (int value){
if (value == this.value) { // 找到就是该节点
return this;
}else if (value < this.value){
if(this.left != null){
return left.search(value);
}else {
return null;
}
}else {
if(this.right != null){
return this.right.search(value);
}else {
return null;
}
}
}
/**
* 查找要删除节点的父节点
* @param value 希望删除的节点
*/
public Node searchParent(int value){
if (this.left != null && this.left.value == value){
return this;
}else if(this.right != null && this.right.value == value){
return this;
}else {
// 如果查找的值 小于当前节点的值 , 并且当前的节点左子节点不为空
if(value < this.value && this.left != null){
return this.left.searchParent(value);
}else if(value >= this.value && this.right != null){
return this.right.searchParent(value);
}else {
// 真的找不到了 没有父节点
return null;
}
}
}
// 添加节点的方法
// 递归添加节点
public void add(Node node){
if (node == null){
return;
}
if(this.value > node.value){
if (this.left != null){
this.left.add(node);
}else {
this.left = node;
}
}else { // 如果value相等 也走右边节点
if (this.right != null){
this.right.add(node);
}else {
this.right = node;
}
}
if (rightHeight() - leftHeight() > 1){
leftRotate();
}
}
// 中序遍历
public void infixOrder(){
if(this.left != null){
this.left.infixOrder();
}
System.out.print(this.value+" ");
if (this.right != null){
this.right.infixOrder();
}
}
}
单旋转 右旋转


// 右旋转
private void rightRotate(){
Node newNode = new Node(value);
// 新节点的有节点指向当前节点的右节点
newNode.right = right;
// 当前节点的左节点指向当前节点的左节点的有节点
newNode.left = left.right;
// 当前节点的值指向当前节点的左子节点的值
value = left.value;
// 当前节点的左子节点 指向当前节点的左子节点的左子节点
left = left.left;
// 当前节点的右子节点 指向新的节点
right = newNode;
}
构造平衡二叉排序树的方法
// 添加节点的方法
// 递归添加节点
public void add(Node node){
if (node == null){
return;
}
if(this.value > node.value){
if (this.left != null){
this.left.add(node);
}else {
this.left = node;
}
}else { // 如果value相等 也走右边节点
if (this.right != null){
this.right.add(node);
}else {
this.right = node;
}
}
// 当添加完一个节点后 如果 右子树的高度 - 左子树的高度>1 发生左旋转
if (rightHeight() - leftHeight() > 1) {
/*if (right != null && right.rightHeight() > right.leftHeight()){
// 先对右子树进行旋转
}*/
leftRotate(); // 左旋转
}
// 当添加完一个节点后 如果 左子树的高度 - 有子树的高度>1 发生右旋转
if (leftHeight() - rightHeight() > 1) {
/*if (right != null && right.rightHeight() > right.leftHeight()){
// 先对右子树进行旋转
}*/
rightRotate(); // 右旋转
}
}
双旋转

代码实现
主要是在生成平衡二叉树的时候进行操作
// 添加节点的方法
// 递归添加节点
public void add(Node node){
if (node == null){
return;
}
if(this.value > node.value){
if (this.left != null){
this.left.add(node);
}else {
this.left = node;
}
}else { // 如果value相等 也走右边节点
if (this.right != null){
this.right.add(node);
}else {
this.right = node;
}
}
// 当添加完一个节点后 如果 右子树的高度 - 左子树的高度>1 发生左旋转
if (rightHeight() - leftHeight() > 1) {
// 如果根节点的右子树的左子树的高度 > 根节点的右子树的右子树的高度
if (right != null && right.rightHeight() > right.leftHeight()){
// 对根节点的右子树进行右旋转
right.rightRotate();
}
leftRotate(); // 左旋转
return; // 必须要
}
// 当添加完一个节点后 如果 左子树的高度 - 有子树的高度>1 发生右旋转
if (leftHeight() - rightHeight() > 1) {
// 如果根节点的左子树的右子树的高度 > 根节点左子树的左子树的的高度
if(left != null && left.rightHeight() > left.leftHeight()){
// 对根节点的左子树进行左旋转
left.leftRotate();
}
rightRotate(); // 右旋转
}
}
多路查找树


2-3树



 插入28
插入28


B树 B+树 B*树





图





快速入门案例

代码实现
package com.cbx.graph;
import java.util.ArrayList;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/10
* @apiNote
*/
public class Graph {
private ArrayList<String> vertexList; // 存储顶点集合
private int[][] edges; // 存储图对应的邻接矩阵
private int numberOfEdges; // 表示边的数目
public static void main(String[] args) {
// 节点的个数
int n = 5;
String[] vertexValue = {"A", "B", "C", "D", "E"};
// 创建图对象
Graph graph = new Graph(n);
// 循环添加节点数据
for (String item : vertexValue) {
graph.insertVertex(item);
}
// 添加边 A-B A-C B-C B-D B-E
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.showGraph();
}
public Graph (int n) {
// 初始化矩阵 和 arrayList
edges = new int[n][n];
vertexList = new ArrayList<>(n);
numberOfEdges = 0;
}
// 图的常用方法
// 1 返回节点的个数
public int getNumberOfVertex() {
return vertexList.size();
}
// 2 得到边的数目
public int getNumberOfEdges() {
return numberOfEdges;
}
// 3 返回节点i(下标) 对应的数据 0->"A" 1->"B"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
// 4. 返回v1 和 v2 边的权值
public int insertVertex(int v1, int v2) {
return edges[v1][v2];
}
// 5. 显示图对应的矩阵
public void showGraph() {
System.out.println("遍历矩阵 ");
for (int[] k : edges) {
System.out.println(Arrays.toString(k));
}
}
// 插入节点
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
// 添加边
/**
*
* @param v1 第一个顶点的下标 第几个顶点
* @param v2 第二个顶点的下标
* @param weight 边的权值
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numberOfEdges++;
}
}
图的深度优先遍历

代码实现
package com.cbx.graph;
import java.util.ArrayList;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/10
* @apiNote
*/
public class Graph {
private ArrayList<String> vertexList; // 存储顶点集合
private int[][] edges; // 存储图对应的邻接矩阵
private int numberOfEdges; // 表示边的数目
private boolean[] isVisited; // 记录节点是否被访问
public static void main(String[] args) {
// 节点的个数
int n = 5;
String[] vertexValue = {"A", "B", "C", "D", "E"};
// 创建图对象
Graph graph = new Graph(n);
// 循环添加节点数据
for (String item : vertexValue) {
graph.insertVertex(item);
}
// 添加边 A-B A-C B-C B-D B-E
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.showGraph();
System.out.println("深度优先遍历");
graph.dfs(); // A->B->C->D->E->
}
public Graph (int n) {
// 初始化矩阵 和 arrayList
edges = new int[n][n];
vertexList = new ArrayList<>(n);
numberOfEdges = 0;
isVisited = new boolean[n];
}
// 得到第一个邻接结点的下标
/**
* 求该结点的第一个邻接矩阵下标
* @param index 该结点的下标
* @return 如果存在就返回对应的下标 否则返回-1
*/
public int getFirstNeighbor(int index) {
for (int j = 0; j < vertexList.size(); j++) {
if (edges[index][j] > 0) {
return j;
}
}
return -1;
}
// 根据前一个邻接节点的下标 获取下一个邻接节点
public int getNextNeighbor(int v1, int v2) {
for (int j = v2 + 1; j < vertexList.size(); j++) {
if (edges[v1][j] > 0) {
return j;
}
}
return -1;
}
// 深度优先遍历方法
public void dfs(boolean[] isVisit, int i) {
// 首先访问该节点
System.out.print(getValueByIndex(i) + "->");
// 将该节点设置已经访问过
isVisit[i] = true;
// 查找下标为i 的邻接节点
int w = getFirstNeighbor(i);
while (w != -1) {
if (!isVisit[w]) { // 没有被访问过
dfs(isVisit, w);
}
// 如果w 被访问过了 去找 下标为i 的节点的 下一个邻接节点的下一个邻接节点
w = getNextNeighbor(i, w);
}
}
// 对dfs 进行重载 遍历所有的节点 并进行 dfs
public void dfs() {
// 回溯遍历dfs
for(int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]) {
dfs(isVisited, i);
}
}
}
// 图的常用方法
// 1 返回节点的个数
public int getNumberOfVertex() {
return vertexList.size();
}
// 2 得到边的数目
public int getNumberOfEdges() {
return numberOfEdges;
}
// 3 返回节点i(下标) 对应的数据 0->"A" 1->"B"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
// 4. 返回v1 和 v2 边的权值
public int insertVertex(int v1, int v2) {
return edges[v1][v2];
}
// 5. 显示图对应的矩阵
public void showGraph() {
System.out.println("遍历矩阵 ");
for (int[] k : edges) {
System.out.println(Arrays.toString(k));
}
}
// 插入节点
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
// 添加边
/**
*
* @param v1 第一个顶点的下标 第几个顶点
* @param v2 第二个顶点的下标
* @param weight 边的权值
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numberOfEdges++;
}
}
图的广度优先遍历



代码实现
// 对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i) {
int u; // 表示队列的头结点的下标
int w; // 邻接节点的下标
// 队列存放访问过的节点 (现进先出)
LinkedList<Integer> queue = new LinkedList<Integer>();
// 访问当前节点
System.out.print(getValueByIndex(i) + "->");
// 标记为已访问
isVisited[i] = true;
// 将节点加入队列
queue.addLast(i);
while (!queue.isEmpty()) {
// 取出对列的头结点坐标
u = queue.removeFirst();
w = getFirstNeighbor(u);
while (w != -1) { //
// 是否访问过
if (!isVisited[w]) {
System.out.print(getValueByIndex(w) + "->");
isVisited[w] = true;
// 入队列
queue.addLast(w);
}
// 已经访问过的话 以u为为前驱 找 w 的下一个邻接结点
w = getNextNeighbor(u, w); // 体现出广度优先
}
}
}
// 遍历所有的节点 都进行广度优先搜索
public void bfs() {
for (int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]) {
bfs(isVisited, i);
}
}
}
图的深度优先 VS 广度优先

总的代码实现
package com.cbx.graph;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
/**
* @author cbx
* @date 2022/1/10
* @apiNote
*/
public class Graph {
private ArrayList<String> vertexList; // 存储顶点集合
private int[][] edges; // 存储图对应的邻接矩阵
private int numberOfEdges; // 表示边的数目
private boolean[] isVisited; // 记录节点是否被访问
public static void main(String[] args) {
// 节点的个数
// int n = 8;
// String[] vertexValue = {"A", "B", "C", "D", "E"};
String[] vertexValue = {"1", "2", "3", "4", "5", "6", "7", "8"};
// 创建图对象
Graph graph = new Graph(vertexValue.length);
// 循环添加节点数据
for (String item : vertexValue) {
graph.insertVertex(item);
}
// 添加边 A-B A-C B-C B-D B-E
/* graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);*/
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
graph.showGraph();
System.out.println("深度优先遍历");
graph.dfs(); // A->B->C->D->E->
System.out.println();
System.out.println("广度优先遍历");
graph.bfs();
}
public Graph (int n) {
// 初始化矩阵 和 arrayList
edges = new int[n][n];
vertexList = new ArrayList<>(n);
numberOfEdges = 0;
isVisited = new boolean[n];
}
// 得到第一个邻接结点的下标
/**
* 求该结点的第一个邻接矩阵下标
* @param index 该结点的下标
* @return 如果存在就返回对应的下标 否则返回-1
*/
public int getFirstNeighbor(int index) {
for (int j = 0; j < vertexList.size(); j++) {
if (edges[index][j] > 0) {
return j;
}
}
return -1;
}
// 根据前一个邻接节点的下标 获取下一个邻接节点
public int getNextNeighbor(int v1, int v2) {
for (int j = v2 + 1; j < vertexList.size(); j++) {
if (edges[v1][j] > 0) {
return j;
}
}
return -1;
}
// 深度优先遍历方法
public void dfs(boolean[] isVisit, int i) {
// 首先访问该节点
System.out.print(getValueByIndex(i) + "->");
// 将该节点设置已经访问过
isVisit[i] = true;
// 查找下标为i 的邻接节点
int w = getFirstNeighbor(i);
while (w != -1) {
if (!isVisit[w]) { // 没有被访问过
dfs(isVisit, w);
}
// 如果w 被访问过了 去找 下标为i 的节点的 下一个邻接节点
w = getNextNeighbor(i, w);
}
}
// 对dfs 进行重载 遍历所有的节点 并进行 dfs
public void dfs() {
isVisited = new boolean[vertexList.size()];
// 回溯遍历dfs
for(int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]) {
dfs(isVisited, i);
}
}
}
// 对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i) {
int u; // 表示队列的头结点的下标
int w; // 邻接节点的下标
// 队列存放访问过的节点 (现进先出)
LinkedList<Integer> queue = new LinkedList<Integer>();
// 访问当前节点
System.out.print(getValueByIndex(i) + "->");
// 标记为已访问
isVisited[i] = true;
// 将节点加入队列
queue.addLast(i);
while (!queue.isEmpty()) {
// 取出对列的头结点坐标
u = queue.removeFirst();
w = getFirstNeighbor(u);
while (w != -1) { //
// 是否访问过
if (!isVisited[w]) {
System.out.print(getValueByIndex(w) + "->");
isVisited[w] = true;
// 入队列
queue.addLast(w);
}
// 已经访问过的话 以u为为前驱 找 下一个邻接结点
w = getNextNeighbor(u, w); // 体现出广度优先
}
}
}
// 遍历所有的节点 都进行广度优先搜索
public void bfs() {
isVisited = new boolean[vertexList.size()];
for (int i = 0; i < vertexList.size(); i++) {
if (!isVisited[i]) {
bfs(isVisited, i);
}
}
}
// 图的常用方法
// 1 返回节点的个数
public int getNumberOfVertex() {
return vertexList.size();
}
// 2 得到边的数目
public int getNumberOfEdges() {
return numberOfEdges;
}
// 3 返回节点i(下标) 对应的数据 0->"A" 1->"B"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
// 4. 返回v1 和 v2 边的权值
public int insertVertex(int v1, int v2) {
return edges[v1][v2];
}
// 5. 显示图对应的矩阵
public void showGraph() {
System.out.println("遍历矩阵 ");
for (int[] k : edges) {
System.out.println(Arrays.toString(k));
}
}
// 插入节点
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
// 添加边
/**
*
* @param v1 第一个顶点的下标 第几个顶点
* @param v2 第二个顶点的下标
* @param weight 边的权值
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numberOfEdges++;
}
}
程序员常用10种算法
二分查找法 非递归

代码实现
package com.cbx.algorithm.binaryseearchnorecursion;
/**
* @author cbx
* @date 2022/1/11
* @apiNote
*/
public class BinarySearchNoRecur {
public static void main(String[] args) {
int[] arr = {1,3, 8, 10, 11, 67, 100};
int i = binarySearch(arr, 100);
System.out.println(i);
}
/**
* 二分查找的非递归实现
* @param arr 带查找的数组 arr 默认是升序排列
* @param target 要查找的目标
* @return -1 表示没有找到
*/
public static int binarySearch(int[] arr, int target) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (arr[mid] == target) {
return mid;
}else if (arr[mid] > target) { // 需要向左边查找
right = mid - 1;
}else { // 需要向右边查找
left = mid + 1;
}
}
return -1;
}
}
分治算法





分治法解决汉诺塔问题 代码实现
package com.cbx.algorithm.dac;
/**
* @author cbx
* @date 2022/1/11
* @apiNote
*/
public class Hanoitower {
public static void main(String[] args) {
hanoiTower(5,'A','B','C');
}
/**
*
* @param num 要移动的个数
* @param a 起始位置
* @param b 中转位置
* @param c 目标位置
*/
public static void hanoiTower(int num, char a, char b, char c) {
// 如果只有一个盘
if (num == 1) {
System.out.println("第1个盘从" + a + "->" + c);
} else {
// 如果我们有n >= 2情况 我们总是可以看做是两个盘 1 最下面的盘 2 上面所有的盘
// 1 先把上面的盘 a - > b 移动过程暂存到c
hanoiTower(num- 1, a, c, b);
// 2 最下面的盘 a - > c
System.out.println("第"+num+"个盘从" + a + "->" + c);
// 3 上面的盘 b - > c 移动过程暂存到a
hanoiTower(num- 1, b, a, c);
}
}
}
动态规划算法





代码实现
package com.cbx.algorithm.dynamic;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/12
* @apiNote
*/
public class DynamicKnapsackProblem {
public static void main(String[] args) {
int[] w = {1,4,3}; // 每个物品的重量
int[] val = {1500, 3000, 2000}; // 物品的价值 val[i]
int m = 4; // 背包的容量
int n = w.length; // 物品的个数
// 创建二维数组
// v[i][j] 表示在前 i 个物品中能够装入容量为 j 的背包中的最大价值
int[][] v = new int[n + 1][m + 1];
// 为了记录放入商品情况 定义一个二维数组
int[][] path = new int[n + 1][m + 1];
// 初始化数组 初始化第一行和第一列, 这里在本程序中,可以不去处理,因为默认就是 0
for (int i = 0; i < v.length; i++) {
v[i][0] = 0;
}
for (int i = 0; i < m + 1; i++) {
v[0][i] = 0;
}
// 根据前面的公式来动态规划处理
for (int i = 1; i < v.length; i++) { // 不处理第一行
for (int j = 1; j < v[0].length; j++) { // 不处理第一列
// 公式
// 1 当 w[i]> j 时:v[i][j]=v[i-1][j]
if (w[i-1] > j ) { // i , j 从1 开始 要 -1
v[i][j] = v[i - 1][j];
}else {
// 2 当 j>=w[i]时: v[i][j]=max{v[i-1][j], val[i]+v[i-1][j-w[i]]} // i 从 1开始
//v[i][j]=Math.max(v[i-1][j], val[i - 1]+v[i-1][j-w[i - 1]]); 为了记录商品存放的情况 不能简单判读大小
if (v[i - 1][j] < val[i - 1] + v[i - 1][j - w[i - 1]]) {
v[i][j] = val[i - 1] + v[i - 1][j - w[i - 1]];
// 把 当前的情况记录到path
path[i][j] = 1;
}else {
v[i][j] = v[i - 1][j];
}
}
}
}
//输出依一下 目前的情况
for (int i = 0; i < v.length; i++) {
System.out.println(Arrays.toString(v[i]));
}
// for (int i = 0; i < v.length; i++) {
// System.out.println(Arrays.toString(path[i]));
// }
// for (int i = 0; i < path.length; i++) { // 这样输出会将所有的放入情况都会遍历 会有冗余
// for (int j = 0; j < path[0].length; j++) {
// if (path[i][j] == 1) {
// System.out.println("第"+i+"个商品发布放入背包");
// }
// }
// }
for (int i = 0;i < path.length;i++){
System.out.println(Arrays.toString(path[i]));
}
int i = path.length - 1; // 行的最大下标
int j = path[0].length - 1; // 列的最大下标
while (i > 0 && j > 0) { // 逆向遍历
if (path[i][j] == 1) {
System.out.println("第"+i+"个商品发布放入背包");
j -= w[i -1]; // 相当于背包减去容量
}
i--;
}
}
}
KMP算法

暴力匹配法

暴力匹配算法 代码实现
package com.cbx.algorithm.kmp;
/**
* @author cbx
* @date 2022/1/13
* @apiNote
*/
public class ViolenceMatch {
public static void main(String[] args) {
// 测试 暴力匹配算法
String str1 = "硅硅谷 尚硅谷你尚硅 尚硅谷你尚硅谷你尚硅你好";
String str2 = "尚硅谷你尚硅你";
System.out.println(violenceMatch(str1, str2));
}
// 暴力匹配算法实现
public static int violenceMatch(String str1, String str2) {
char[] s1 = str1.toCharArray();
char[] s2 = str2.toCharArray();
int s1Len = str1.length();
int s2Len = str2.length();
int i = 0; // i索引指向s1
int j = 0; // j索引指向s2
while (i < s1Len && j < s2.length) { // 保证不越界
if(s1[i] == s2[j]) { // 匹配成功
i++;j++;
}else {
i = i -( j - 1);
j = 0;
}
}
// 判断是否匹配成功
if (j == s2Len) {
return i - j;
} else {
return -1;
}
}
}
KMP算法

:https://www.cnblogs.com/ZuoAndFutureGirl/p/9028287.html






KMP算法 代码实现
package com.cbx.algorithm.kmp;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/13
* @apiNote
*/
public class KMPMatch {
public static void main(String[] args) {
String str1 = "BBC ABCDABABC DABCDABDE";
String str2 = "ABCDABD";
//String str2 = "BBC";
int[] next = KMPNext(str2);
System.out.println("部分匹配表" + Arrays.toString(next));
System.out.println("匹配字段的起始位置" + KMPSearch(str1, str2, next)); // 15
}
/**
* 写出KMP搜索算法
* @param str1 原字符串
* @param str2 子串
* @param next 部分匹配表 是子串的部分匹配表
* @return -1 为没有匹配到 否则返回第一个匹配的位置
*/
public static int KMPSearch(String str1, String str2, int[] next) {
// 遍历
for (int i = 0, j = 0; i < str1.length(); i++) {
// 需要处理 str1.charAt(i) != str2.charAt(j), 调整 j 的 大小
// KMP代码的核心点
while (j > 0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j - 1];
}
if (str1.charAt(i) == str2.charAt(j)) {
j++;
}
if (j == str2.length()) { //j==7
return i - j + 1;
}
}
return -1;
}
// 获取一个字符串(子串)的部分匹配
public static int[] KMPNext (String str) {
int[] next = new int[str.length()];
next[0] = 0; // 如果字符传长度为1 部分匹配值为0
for (int i = 1, j = 0; i < str.length(); i++) {
// 当str.charAt(i) != str.charAt(j) 需要从next[j - 1]获取新得节点
// 直到发现有str.charAt(i) == str.charAt(j)成立时推出
// KMP算法的核心
while (j > 0 && str.charAt(i) != str.charAt(j)) {
j = next[j - 1];
}
// 满足str.charAt(i) == str.charAt(j)条件时 部分匹配值 + 1
if (str.charAt(i) == str.charAt(j)) {
j++;
}
next[i] = j;
}
return next;
}
}
贪心算法




代码实现
package com.cbx.algorithm.greedy;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
/**
* @author cbx
* @date 2022/1/14
* @apiNote
*/
public class GreedyAlgorithm {
public static void main(String[] args) {
// 创建广播电台 放入Map
Map<String, HashSet<String>> broadcast = new HashMap<>();
// 将各个电台放入HashSet
HashSet<String> hashSet1 = new HashSet<>();
hashSet1.add("北京");
hashSet1.add("上海");
hashSet1.add("天津");
HashSet<String> hashSet2 = new HashSet<>();
hashSet2.add("广州");
hashSet2.add("上海");
hashSet2.add("深圳");
HashSet<String> hashSet3 = new HashSet<>();
hashSet3.add("成都");
hashSet3.add("上海");
hashSet3.add("杭州");
HashSet<String> hashSet4 = new HashSet<>();
hashSet4.add("上海");
hashSet4.add("天津");
HashSet<String> hashSet5 = new HashSet<>();
hashSet5.add("杭州");
hashSet5.add("大连");
broadcast.put("k1", hashSet1);
broadcast.put("k2", hashSet2);
broadcast.put("k3", hashSet3);
broadcast.put("k4", hashSet4);
broadcast.put("k5", hashSet5);
// 存放所有地区
HashSet<String> allArea = new HashSet<>();
for (Map.Entry<String, HashSet<String>> entity : broadcast.entrySet()) {
allArea.addAll(entity.getValue());
}
// 可以输出验证一波
// for (String s : allArea) {
// System.out.println(s);
// }
// 创建 ArrayList存放选择的电台集合
ArrayList<String> selects = new ArrayList<>();
// 定义一个临时集合 在遍历过程中 存放遍历过程中的电台覆盖的地区和当前还没有覆盖的地区的交集
HashSet<String> tempSet = new HashSet<>();
// 定义一个maxKey 保存在一次遍历过程中 能够覆盖最大覆盖的地区对应的电台key
// 如果maxKey 不为null 则会加入selects里
String maxKey = "";
while (allArea.size() != 0) { // 如果allArea > 0 则还没有覆盖所有的地区
maxKey = ""; // 每个循环需要对maxKey清空
// 遍历broadcast. 取出对应的ekey
for (String key : broadcast.keySet()) {
tempSet.clear(); // tempSet 每个循环要清空
// areas 当前的key(电台) 能够覆盖的地区
HashSet<String> areas = broadcast.get(key);
tempSet.addAll(areas);
// 取出tempSet 与 allAreas 集合的交集 retainAll 方法 将交集的部分赋值给tempSet
tempSet.retainAll(allArea);
// 如果当前这个集合包含的未覆盖的地区的数量 比maxKey 指向集合为覆盖的地区的多 将 maxSize重新赋值
if (tempSet.size() > 0 && ("".equals(maxKey) || tempSet.size() > broadcast.get(maxKey).size())) {
maxKey = key;
}
}
// 如果maxKey的长度不为0 将 maxKey加入到selects
if (!"".equals(maxKey)) {
selects.add(maxKey);
// 将maxKey指向的广播电台覆盖的地区, 从allAreas 去掉
allArea.removeAll(broadcast.get(maxKey));
}
}
System.out.println("得到的集合为:"+ selects); //得到的集合为:[k1, k2, k3, k5]
}
}
普利姆算法 Prim





代码实现
package com.cbx.algorithm.prim;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/15
* @apiNote
*/
public class PrimAlgorithm {
public static void main(String[] args) {
char[] data = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
int verxs = data.length;
//邻接矩阵的关系使用二维数组表示,10000 这个大数,表示两个点不联通
int [][]weight=new int[][]{
{10000,5,7,10000,10000,10000,2}, // A
{5,10000,10000,9,10000,10000,3}, // B
{7,10000,10000,10000,8,10000,10000}, // C
{10000,9,10000,10000,10000,4,10000}, // D
{10000,10000,8,10000,10000,5,4}, // E
{10000,10000,10000,4,5,10000,6}, // F
{2,3,10000,10000,4,6,10000},}; // G
// A B C D E F G
MGraph mGraph = new MGraph(verxs);
// 创建 MinTree 对象
MinTree minTree = new MinTree();
minTree.creatGraph(mGraph, verxs, data, weight);
minTree.showGraph(mGraph);
// 测试Prim算法
minTree.prim(mGraph, 0);
}
}
// 创建最小生成树 -> 村庄的通路问题
class MinTree {
/**
* 创建图的邻接矩阵
* @param graph 图的对象
* @param verxs 图的个数
* @param data 图的各个顶点的值
* @param weight 图的邻接矩阵
*/
public void creatGraph(MGraph graph, int verxs, char[] data, int[][] weight) {
for (int i = 0; i < verxs; i++) {
graph.data[i] = data[i];
System.arraycopy(weight[i], 0, graph.weight[i], 0, verxs);
/* for (int j = 0; j < verxs; j++) {
graph.weight[i][j] = weight[i][j];
}*/
}
}
public void showGraph(MGraph graph) {
for (int i = 0; i < graph.verx; i++) {
System.out.println(Arrays.toString(graph.weight[i]));
}
}
/**
* 编写一个Prim算法 得到最小生成树
* @param graph 图
* @param v 表示从图的第几个顶点开始生成 'A'开始生成 传入 0 如果想从B开始生成 传入 1 ....
*/
public void prim (MGraph graph, int v) {
int[] visited = new int[graph.verx]; // 标记节点是否被访问 java默认都是 0 其他语言可能需要初始化一下;
visited[v] = 1;
// h1 和 h2 记录两个顶点的下标
int h1 = -1;
int h2 = -1;
int minWeight = 10000; // 初始化成一个大数
for (int k = 1; k < graph.verx; k++) { // 因为有 graph.verx 个顶点 结果会有 graph.verx-1 条边 所以直接从1 开始
// 遍历每一次生成的子图 找到和哪个节点的距离最近
for (int i = 0; i < graph.verx; i++) { // i 表示被访问过的节点
for (int j = 0; j < graph.verx; j++) { // j 表示还没被访问过的节点
if (visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) {
// 替换 minWeight (寻找已经访问过的节点间的权值最小的边) 看不懂去看图 卢意!!!
minWeight = graph.weight[i][j];
h1 = i;
h2 = j;
}
}
}
// 找到一条边就是最小的
System.out.println("边" + graph.data[h1] + "-----" + graph.data[h2] + " 距离= " + minWeight);
minWeight = 10000;
visited[h2] = 1;
}
}
}
class MGraph {
int verx; // 表示图的节点的个数
char[] data; //存放 节点的数据
int[][] weight; // 存放边和权值 (邻接矩阵)
public MGraph(int verx) {
this.verx = verx;
data = new char[verx];
weight = new int[verx][verx];
}
}
下面是 System.arrayCopy的源代码声明 :
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
代码解释:
Object src : 原数组
int srcPos : 从元数据的起始位置开始
Object dest : 目标数组
int destPos : 目标数组的开始起始位置
int length : 要copy的数组的长度
比如 :我们有一个数组数据 byte[] srcBytes = new byte[]{2,4,0,0,0,0,0,10,15,50}; // 源数组
byte[] destBytes = new byte[5]; // 目标数组
我们使用System.arraycopy进行转换(copy)
System.arrayCopy(srcBytes,0,destBytes ,0,5)
上面这段代码就是 : 创建一个一维空数组,数组的总长度为 12位,然后将srcBytes源数组中 从0位 到 第5位之间的数值 copy 到 destBytes目标数组中,在目标数组的第0位开始放置.
那么这行代码的运行效果应该是 2,4,0,0,0,
克鲁斯卡尔算法 kruskal







代码实现
package com.cbx.algorithm.kruskal;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/16
* @apiNote
*/
public class KruskalCase {
private int edgeNum; // 边的个数
private char[] vertex; // 顶点数组
private int[][] matrix; // 邻接矩阵
private static final int INF = Integer.MAX_VALUE; // 使用INF变量表示两个顶点不能联通
public static void main(String[] args) {
char[] vertex = new char[]{'A', 'B', 'C', 'D', 'E', 'F', 'G'};
//克鲁斯卡尔算法的邻接矩阵
int matrix[][] = { // 自己和自己为0
/*A*//*B*//*C*//*D*//*E*//*F*//*G*/
/*A*/ { 0, 12, INF, INF, INF, 16, 14},
/*B*/ { 12, 0, 10, INF, INF, 7, INF},
/*C*/ { INF, 10, 0, 3, 5, 6, INF},
/*D*/ { INF, INF, 3, 0, 4, INF, INF},
/*E*/ { INF, INF, 5, 4, 0, 2, 8},
/*F*/ { 16, 7, 6, INF, 2, 0, 9},
/*G*/ { 14, INF, INF, INF, 8, 9, 0}};
// 创建克鲁斯卡尔的对象实例
KruskalCase kruskalCase = new KruskalCase(vertex, matrix);
kruskalCase.show();
EData[] edges = kruskalCase.getEdges();
System.out.println("未排序");
System.out.println(Arrays.toString(edges));
System.out.println("排序后");
kruskalCase.sortEdges(edges);
System.out.println(Arrays.toString(edges));
kruskalCase.kruskal();
System.out.println();
}
public KruskalCase(char[] vertex, int[][] matrix) {
// 初始化顶点数和边的个数
this.vertex = vertex;
this.matrix = matrix;
for (int i = 0; i < vertex.length; i++) {
for (int j = i + 1; j < vertex.length; j++) {
if (this.matrix[i][j] != INF) { // 判断可以联通
edgeNum ++;
}
}
}
}
// 打印邻接矩阵
public void show() {
System.out.println("邻接矩阵为:");
for (int[] arr : matrix) {
System.out.println(Arrays.toString(arr));
}
}
/* *//**
* 对边进行排序处理 用我最不熟系的对排序进行排序
*//*
private void heapSort(EData[] eData) {
for (int i = eData.length / 2 - 1; i >=0; i--) {
adjustHeap(eData,i, eData.length);
}
EData temp;
for (int i = eData.length - 1; i > 0; i--) {
temp = eData[i];
eData[i] = eData[0];
eData[0] = temp;
adjustHeap(eData, 0, i);
}
System.out.println(Arrays.toString(eData));
}
private void adjustHeap(EData[] eData, int i, int length) {
EData temp = eData[i];
for (int k = i * 2 +1; k < length; k = k * 2 + 1) {
if (k + 1 < length && eData[k + 1].weight > eData[k].weight) {
k++;
}
if (eData[k].weight > temp.weight) {
eData[i] = eData[k];
i = k;
} else {
break;
}
}
eData[i] = temp;
}
*/
/**
* 功能:对边进行排序处理,冒泡排序
* @param edges 边的集合
*/
private void sortEdges(EData[] edges){
for (int i = 0; i < edges.length-1; i++) {
for (int j = 0; j < edges.length - 1 - i; j++) {
if (edges[j].weight > edges[j+1].weight){
EData tmp = edges[j];
edges[j] = edges[j+1];
edges[j+1] = tmp;
}
}
}
}
/**
* @param ch 顶点的值 'A'
* @return 返回对应顶点的下标
*/
private int getPosition(char ch) {
for (int i = 0; i < vertex.length; i++) {
if (vertex[i] == ch) {
return i;
}
}
return -1;
}
/**
* 获取图中的边 EData[]放入数组中 后面需要遍历该数组
* 通过matrix邻接矩阵来获取
* EData[] 形式 [['A', 'B', 12],['B', 'F', 7] .....]
* @return
*/
private EData[] getEdges() {
int index = 0;
EData[] edges = new EData[edgeNum];
for (int i = 0; i < vertex.length; i++) {
for (int j = i + 1; j < vertex.length; j++) {
if (matrix[i][j] != INF) {
edges[index++] = new EData(vertex[i], vertex[j], matrix[i][j]);
}
}
}
return edges;
}
/**
* 获取下标为i的顶点的终点 用于判断两个顶点的终点是否相同
* @param ends 记录了各个顶点对应的终点的下标是哪个 动态生成的
* @param i 传入的顶点对应的下标
* @return 返回下标为i 的顶点的终点对应的下标
*/
private int getEnd(int [] ends, int i) {
while (ends[i] != 0) {
i = ends[i];
}
return i;
}
// kruskal最小生成数算法
public void kruskal() {
int index = 0; // 最后结果数组的索引
int[] ends = new int[edgeNum]; // 用于保存"已有最小生成数" 中的每个顶点 在最小生成数中的每个终点
// 创建结果数组 保存最后的生成数
EData[] res = new EData[edgeNum];
// 获取图中所有所有边的集合 一个有12条边
EData[] edges = getEdges();
sortEdges(edges);
// 按边的权值从小到大排序
// 遍历edges 数组, 将边添加到最小生成树中, 判断是准备加入的边是否形成回路, 如果没有 则加入res
int p1;
int p2;
for (int i = 0; i < edgeNum; i++) {
// 获取到第i条边的第一个顶点 (起点)
p1 = getPosition(edges[i].start);
// 获取到第i条边的第二个顶点 (终点)
p2 = getPosition(edges[i].end);
// 获取 p1 这个顶点在已有的最小生成数中的终点是哪个
int m = getEnd(ends, p1);
// 获取 p2 这个顶点在已有的最小生成数中的终点是哪个
int n = getEnd(ends, p2);
// 判断是否构成回路
if (m != n) { // 不构成回路
ends[m] = n; // 设置m在"当前最小生成数" 中的终点为 n
res[index++] = edges[i];
}
}
for (int i = 0; i < index ; i++) {
System.out.println(res[i]);
}
}
// 打印和统计最小生成数
public void showRes() {
}
}
/**
* 创建一个类EData 它的对象实例就表示一条边
*/
class EData {
char start; // 边的一个点 可以理解为起点
char end; // 边的另外一个顶点 可以理解为终点
int weight; // 边的权值
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public String toString() {
return "EData{" +
"start=" + start +
", end=" + end +
", weight=" + weight +
'}';
}
}
迪杰斯特拉算法 Dijkstra





代码实现
package com.cbx.algorithm.dijkstra;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/17
* @apiNote
*/
public class DijkstraAlgorithm {
public static final int INF = 65535; // 表示不可连接 不能Integer的最大值哦 超过了就变负数了 就有问题了
public static void main(String[] args) {
char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
// 邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
matrix[0]=new int[]{INF,5,7,INF,INF,INF,2};
matrix[1]=new int[]{5,INF,INF,9,INF,INF,3};
matrix[2]=new int[]{7,INF,INF,INF,8,INF,INF};
matrix[3]=new int[]{INF,9,INF,INF,INF,4,INF};
matrix[4]=new int[]{INF,INF,8,INF,INF,5,4};
matrix[5]=new int[]{INF,INF,INF,4,5,INF,6};
matrix[6]=new int[]{2,3,INF,INF,4,6,INF};
// 创建图的对象
Graph graph = new Graph(vertex, matrix);
// 测试 看看邻接矩阵是否ok
graph.showGraph();
// 测试迪杰斯特拉算法
graph.dsj(6);
graph.showDijkstra();
}
}
// 创建一个图类
class Graph {
private char[] vertex; // 存放顶点数组
private int[][] matrix; // 邻接矩阵
private VisitedVertex visitedVertex; // 已经访问顶点的集合
public Graph(char[] vertex, int[][] matrix) {
this.vertex = vertex;
this.matrix = matrix;
}
// 显示图的方法
public void showGraph() {
for (int[] arr : matrix) {
System.out.println(Arrays.toString(arr));
}
}
// 显示结果
public void showDijkstra() {
visitedVertex.show();
}
/**
* 迪杰斯特拉算法实现
* @param index
*/
public void dsj(int index) {
this.visitedVertex = new VisitedVertex(vertex.length, index);
update(index); // 更新index顶点 到周围顶点的距离和前驱顶点
for (int i = 1; i < vertex.length; i++) {
index = visitedVertex.updateArr(); // 选择并返回新的访问顶点
update(index); // 更新index顶点 到周围顶点的距离和前驱顶点
}
}
// 更新index 下标顶点周围顶点的距离 和周围顶点的前驱顶点
private void update(int index) {
int length = 0;
// 根据邻接矩阵的 index行
for (int j = 0; j < matrix[index].length; j++) {
// len 的含义是 出发顶点到index顶点的距离 + 从index顶点的距离到 j顶点的距离
length = visitedVertex.getDis(index) + matrix[index][j];
// 如果j的顶点没有被访问过 并 小于出发顶点到j顶点的距离就需要更新
if (!visitedVertex.in(j) && length < visitedVertex.getDis(j)) {
visitedVertex.updatePre(j, index); // 更新j顶点的前驱为index顶点
visitedVertex.updateDis(j, length); // 更新出发顶点到j节点的距离
}
}
}
}
// 已访问顶点的类
class VisitedVertex {
// 记录每个顶点是否访问过 1表示访问过,0表示未访问, 会动态更新
public int[] already_arr;
// 每个下标对应的值为第一个顶点的下标, 会动态更新
public int[] pre_visited;
// 记录出发顶点到洽谈所有顶点的距离 比如G为出发顶点 就会记录G到其他顶点的距离 会动态更新 求的最短距离会放到dis
public int[] dis;
/**
* 构造器
* @param length 数组的长度 也是节点的个数
* @param index 出发顶点对应的下标
*/
public VisitedVertex(int length, int index) {
this.already_arr = new int[length];
this.pre_visited = new int[length];
this.dis = new int[length];
// 初始化dis数组 都为不可到达的值
Arrays.fill(dis, DijkstraAlgorithm.INF);
// 设置出发顶点被访问过
this.already_arr[index] = 1;
// 自己的对应下标的值为0 也代表不可达
this.dis[index] = 0;
}
/**
* 判断index顶点是否被访问过
* @param index
* @return 如果访问过返回 true 否则 false
*/
public boolean in(int index) {
return already_arr[index] == 1;
}
/**
* 更新出发顶点到index顶点的距离
* @param index
* @param len
*/
public void updateDis(int index, int len) {
dis[index] = len;
}
/**
* 更新pre为索引的顶点的前驱为index索引的节点
* @param pre
* @param index
*/
public void updatePre(int pre, int index) {
pre_visited[pre] = index;
}
/**
* 返回出发顶点到index顶点的距离
* @param index
*/
public int getDis(int index) {
return dis[index];
}
/**
* 继续选择滨返回新的访问节点, 比如这里的G 完后 就是A作为新的访问顶点 (注意不是出发点)
* @return
*/
public int updateArr() {
int min = DijkstraAlgorithm.INF;
int index = 0;
for (int i = 0; i < already_arr.length; i++) {
if (already_arr[i] == 0 && dis[i] < min) {
min = dis[i];
index = i;
}
}
already_arr[index] = 1;
return index;
}
// 显示最后的结果
// 将三个数组的情况输出
public void show() {
System.out.println("==================================");
System.out.println("array_arr:");
for (int i : already_arr) {
System.out.print(i + " " );
}
System.out.println();
System.out.println("pre_visited:");
for (int i : pre_visited) {
System.out.print(i + " " );
}
System.out.println();
System.out.println("dis:");
for (int i : dis) {
System.out.print(i + " " );
}
System.out.println();
//为了好看最后的最短距离,我们处理
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
int count = 0;
for (int i : dis) {
if (i != 65535) {
System.out.print(vertex[count] + "("+i+") ");
} else {
System.out.println("N ");
}
count++;
}
System.out.println();
}
}
弗洛伊德算法





代码实现
package com.cbx.algorithm.floyd;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/18
* @apiNote
*/
public class FloydAlgorithm {
public static void main(String[] args) {
// 测试看看图是否创建成功
char[] vertex = { 'A', 'B', 'C', 'D', 'E', 'F', 'G' };
//创建邻接矩阵
int[][] matrix = new int[vertex.length][vertex.length];
final int N = 65535;
matrix[0] = new int[] { 0, 5, 7, N, N, N, 2 };
matrix[1] = new int[] { 5, 0, N, 9, N, N, 3 };
matrix[2] = new int[] { 7, N, 0, N, 8, N, N };
matrix[3] = new int[] { N, 9, N, 0, N, 4, N };
matrix[4] = new int[] { N, N, 8, N, 0, 5, 4 };
matrix[5] = new int[] { N, N, N, 4, 5, 0, 6 };
matrix[6] = new int[] { 2, 3, N, N, 4, 6, 0 };
//创建 Graph 对象
GraphFloyd graph = new GraphFloyd(vertex.length, matrix, vertex);
//调用弗洛伊德算法
graph.floyd();
graph.show();
}
}
// 创建图
class GraphFloyd {
private char[] vertex; // 存放顶点的数组
private int[][] dis; // 记录从各个顶点出发 到其他顶点的距离, 最后的结果 , 也是流在该时数组
private int[][] pre; // 保存到达目标结点的前驱节点
/**
*
* @param length 顶点的个数
* @param matrix 邻接表
* @param vertex 顶点数组
*/
GraphFloyd(int length, int[][] matrix, char[] vertex) {
this.vertex = vertex;
this.dis = matrix;
this.pre = new int[length][length];
// 对pre数组初始化, 存放的是前驱顶点的下标 初始化每一行都是当前节点的下标
for (int i = 0; i < length; i++) {
Arrays.fill(pre[i], i);
}
}
// 显示pre数组 和 dis数组
public void show() {
char[] vertex = {'A', 'B', 'C', 'D', 'E', 'F', 'G'};
for (int k = 0; k < dis.length; k++) {
// 先将 pre 数组输出的一行
for (int i = 0; i < dis.length; i++) {
System.out.print(vertex[pre[k][i]] + " ");
}
System.out.println();
// 输出 dis 数组的一行数据
for (int i = 0; i < dis.length; i++) {
System.out.print("(" + vertex[k] + "到" + vertex[i] + "的最短路径是" + dis[k][i] + ") ");
}
System.out.println();
System.out.println();
}
}
/**
* 弗洛伊德算法
*/
public void floyd() {
// 保存变量
int len;
// 从中间顶点的变量 k是中间顶点的下标
for (int k = 0; k < dis.length; k++) {
// 从 i 顶点开始出发 'A', 'B', 'C', 'D', 'E', 'F', 'G'
for (int i = 0; i < dis.length; i++) {
// 到达j 顶点
for (int j = 0; j < dis.length; j++) {
len = dis[i][k] + dis[k][j]; // 求出从i顶点出发 经过k 的中间顶点 到达j顶点的路离
if (len < dis[i][j]) { // 小于直连的值 取经过其他顶点的的值
dis[i][j] = len; // 更新距离表
pre[i][j] = pre[k][j]; // 更新前驱顶点
}
}
}
}
}
}
马踏棋盘算法



代码实现 (会很慢)
package com.cbx.algorithm.horse;
import java.awt.*;
import java.util.ArrayList;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/19
* @apiNote
*/
public class HorseChessboard {
private static int x; // 棋盘的列
private static int y; // 棋盘的行
// 创建一个数组 标记各个位置是否被访问过
private static boolean[] visited;
// 使用一个属性 标记棋盘的所有位置是否被 访问过
private static boolean finished;
// static int count = 0;
public static void main(String[] args) {
// 测试
x = 6;
y = 6;
int row = 2; // 马儿初始位置的行
int clo = 4; // 马儿初始位置的列
// 创建棋盘
int [][] chessboard = new int[x][y];
visited = new boolean[x * y]; // 初始值都是false
// 测试一下花费时间
long start = System.currentTimeMillis();
System.out.println("开始时间 " + start);
traversalChessBoard(chessboard, row - 1, clo - 1, 1);
long end = System.currentTimeMillis();
System.out.println("结束时间 " + end);
System.out.println("功共耗时 " + (end - start) + "毫秒");
System.out.println("输出结果");
for (int[] arr : chessboard) {
System.out.println(Arrays.toString(arr));
}
}
/**
* 完成马踏棋盘算法
* @param chessboard 棋盘
* @param row 马儿当前位置的行
* @param col 马儿当前位置的列
* @param step 表示马儿走的是第几步 初始位置是第一步
*/
public static void traversalChessBoard(int[][] chessboard, int row, int col, int step) {
// System.out.println("第"+(++count)+"次比较");
chessboard[row][col] = step;
// 若第四行 row=4 x为 8 clo = 4 4 * 8 = 4 = 36 (从1开始 所以 37 -1 = 36) 看图!!!
visited[row * x + col] = true; // 标记已访问
// 获取下一比的位置的集合
ArrayList<Point> ps = next(new Point(col, row));
// 遍历ps
while (!ps.isEmpty()) {
// 取出下一个可以走的位置
Point p = ps.remove(0);
// 判断该点 是否已经访问过
if (!visited[p.y * x + p.x]) {
// 没有访问过
traversalChessBoard(chessboard, p.y, p.x , step + 1);
}
}
// 判断是否完成任务
// 1 step < x * y 情况有两种 棋盘到目前位置 棋盘为走完
// 2 棋盘处于回溯过程
if (step < x * y && !finished) {
chessboard[row][col] = 0;
visited[row * x + col] = false;
}else {
finished = true;
}
}
/**
* 根据当前的位置(根据point对象) 计算马儿还能走哪些位置 并放入到一个集合中(arrayList),最多有8个位置
* @param curPoint 当前位置
* @return
*/
public static ArrayList<Point> next(Point curPoint) {
// 创建一个ArrayList
ArrayList<Point> ps = new ArrayList<>();
/// 创建一个point对象
Point p1 = new Point();
// 判断可不可以走可以走 图中'5'的位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y - 1) >= 0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'6'的位置
if ((p1.x = curPoint.x -1 ) >= 0 && (p1.y = curPoint.y - 2) >=0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'7'的位置
if ((p1.x = curPoint.x + 1) < x && (p1.y = curPoint.y - 2) >=0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'0'的位置
if ((p1.x = curPoint.x + 2) < x && (p1.y = curPoint.y - 1) >=0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'1'的位置
if ((p1.x = curPoint.x + 2) < x && (p1.y = curPoint.y + 1) < y) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'2'的位置
if ((p1.x = curPoint.x + 1) < x && (p1.y = curPoint.y + 2) < y) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'3'的位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < y) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'4'的位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < y) {
ps.add(new Point(p1));
}
return ps;
}
}
贪心法优化
package com.cbx.algorithm.horse;
import java.awt.*;
import java.util.ArrayList;
import java.util.Arrays;
/**
* @author cbx
* @date 2022/1/19
* @apiNote
*/
public class HorseChessboard {
private static int x; // 棋盘的列
private static int y; // 棋盘的行
// 创建一个数组 标记各个位置是否被访问过
private static boolean[] visited;
// 使用一个属性 标记棋盘的所有位置是否被 访问过
private static boolean finished;
// static int count = 0;
public static void main(String[] args) {
// 测试
x = 8;
y = 8;
int row = 1; // 马儿初始位置的行
int clo = 1; // 马儿初始位置的列
// 创建棋盘
int [][] chessboard = new int[x][y];
visited = new boolean[x * y]; // 初始值都是false
// 测试一下花费时间
long start = System.currentTimeMillis();
System.out.println("开始时间 " + start);
traversalChessBoard(chessboard, row - 1, clo - 1, 1);
long end = System.currentTimeMillis();
System.out.println("结束时间 " + end);
System.out.println("功共耗时 " + (end - start) + "毫秒");
System.out.println("输出结果");
for (int[] arr : chessboard) {
System.out.println(Arrays.toString(arr));
}
}
/**
* 完成马踏棋盘算法
* @param chessboard 棋盘
* @param row 马儿当前位置的行
* @param col 马儿当前位置的列
* @param step 表示马儿走的是第几步 初始位置是第一步
*/
public static void traversalChessBoard(int[][] chessboard, int row, int col, int step) {
// System.out.println("第"+(++count)+"次比较");
chessboard[row][col] = step;
// 若第四行 row=4 x为 8 clo = 4 4 * 8 = 4 = 36 (从1开始 所以 37 -1 = 36) 看图!!!
visited[row * x + col] = true; // 标记已访问
// 获取下一比的位置的集合
ArrayList<Point> ps = next(new Point(col, row));
sort(ps);
// 遍历ps
while (!ps.isEmpty()) {
// 取出下一个可以走的位置
Point p = ps.remove(0);
// 判断该点 是否已经访问过
if (!visited[p.y * x + p.x]) {
// 没有访问过
traversalChessBoard(chessboard, p.y, p.x , step + 1);
}
}
// 判断是否完成任务
// 1 step < x * y 情况有两种 棋盘到目前位置 棋盘为走完
// 2 棋盘处于回溯过程
if (step < x * y && !finished) {
chessboard[row][col] = 0;
visited[row * x + col] = false;
}else {
finished = true;
}
}
/**
* 根据当前的位置(根据point对象) 计算马儿还能走哪些位置 并放入到一个集合中(arrayList),最多有8个位置
* @param curPoint 当前位置
* @return
*/
public static ArrayList<Point> next(Point curPoint) {
// 创建一个ArrayList
ArrayList<Point> ps = new ArrayList<>();
/// 创建一个point对象
Point p1 = new Point();
// 判断可不可以走可以走 图中'5'的位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y - 1) >= 0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'6'的位置
if ((p1.x = curPoint.x -1 ) >= 0 && (p1.y = curPoint.y - 2) >=0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'7'的位置
if ((p1.x = curPoint.x + 1) < x && (p1.y = curPoint.y - 2) >=0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'0'的位置
if ((p1.x = curPoint.x + 2) < x && (p1.y = curPoint.y - 1) >=0) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'1'的位置
if ((p1.x = curPoint.x + 2) < x && (p1.y = curPoint.y + 1) < y) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'2'的位置
if ((p1.x = curPoint.x + 1) < x && (p1.y = curPoint.y + 2) < y) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'3'的位置
if ((p1.x = curPoint.x - 1) >= 0 && (p1.y = curPoint.y + 2) < y) {
ps.add(new Point(p1));
}
// 判断可不可以走可以走 图中'4'的位置
if ((p1.x = curPoint.x - 2) >= 0 && (p1.y = curPoint.y + 1) < y) {
ps.add(new Point(p1));
}
return ps;
}
// 根据当前这一步的左右的下一步的选择位置 进行非递减排序(前后两个数组可能相同的递增排序) 1,2,3,3,4,5,8,8:非递减排列,选择第一个 减少回溯次数
public static void sort(ArrayList<Point> ps) {
ps.sort((o1, o2) -> {
// 现获取到o1的下一步的所有位置的个数
ArrayList<Point> arr1 = next(o1);
ArrayList<Point> arr2 = next(o2);
if (arr1.size() < arr2.size()) {
return -1;
} else if (arr1.size() > arr2.size()) {
return 1;
}else {
return 0;
}
});
}
}


评论