
小厂后端面试题
1、Redis的key和value可以存储的最大值分别是多少?
- 虽然Key的大小上限为
512M,但是一般建议key的大小不要超过1KB,这样既可以节约存储空间,又有利于Redis进行检索。 - value的最大值也是
512M。对于String类型的value值上限为512M,而集合、链表、哈希等key类型,单个元素的value上限也为512M。
2. 怎么利用Redis实现数据的去重?
- Redis的
set:它可以去除重复元素,也可以快速判断某一个元素是否存在于集合中,如果元素很多(比如上亿的计数),占用内存很大。 - Redis的
bit:它可以用来实现比set内存高度压缩的计数,它通过一个bit设置为1或者0,表示存储某个元素是否存在信息。例如网站唯一访客计数,可以把user_id作为 bit 的偏移量 offset,如设置为1表示有访问,使用1 MB的空间就可以存放800多万用户的一天访问计数情况。 HyperLogLog:实现超大数据量精确的唯一计数都是比较困难的,HyperLogLog可以仅仅使用 12 k左右的内存,实现上亿的唯一计数,而且误差控制在百分之一左右。bloomfilter布隆过滤器:布隆过滤器是一种占用空间很小的数据结构,它由一个很长的二进制向量和一组Hash映射函数组成,它用于检索一个元素是否在一个集合中
3. Redis什么时候需要序列化?Redis序列化的方式有哪些?
- 比如想把内存中的对象状态保存到一个文件中或者数据库中的时候(最常用,如保存到redis);
- 再比喻想用套接字在网络上传送对象的时候,都需要序列化。
RedisSerializer接口 是 Redis 序列化接口,用于 Redis KEY 和 VALUE 的序列化
- JDK 序列化方式 (默认)
- String 序列化方式
- JSON 序列化方式
- XML 序列化方式
4、线程池的状态有哪些?获取多线程并发执行结果的方式有哪些?
线程池和线程的状态是不一样的哈,线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
RUNNING
- 该状态的线程池会接收新任务,并处理阻塞队列中的任务;
- 调用线程池的
shutdown()方法,可以切换到SHUTDOWN状态; - 调用线程池的
shutdownNow()方法,可以切换到STOP状态;
SHUTDOWN
- 该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- 队列为空,并且线程池中执行的任务也为空,进入TIDYING状态;
STOP
- 该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- 线程池中执行的任务为空,进入TIDYING状态;
TIDYING
- 该状态表明所有的任务已经运行终止,记录的任务数量为0。
terminated()执行完毕,进入TERMINATED状态
TERMINATED
- 该状态表示线程池彻底终止
5. 线程池原理?各个参数的作用。
ThreadPoolExecutor的构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime,TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
几个核心参数的作用:
- corePoolSize:线程池核心线程数最大值
- maximumPoolSize:线程池最大线程数大小
- keepAliveTime:线程池中非核心线程空闲的存活时间大小
- unit:线程空闲存活时间单位
- workQueue:存放任务的阻塞队列
- threadFactory:用于设置创建线程的工厂,可以给创建的线程设置有意义的名字,可方便排查问题。
- handler: 线城池的拒绝策略事件,主要有四种类型。
四种饱和拒绝策略
- AbortPolicy(抛出一个异常,默认的)
- DiscardPolicy(直接丢弃任务)
- DiscardOldestPolicy(丢弃队列里最老的任务,将当前这个任务继续提交给线程池)
- CallerRunsPolicy(交给线程池调用所在的线程进行处理)
线程池原理:
- 提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
- 如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
- 当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
- 如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
6. ThreadLocal的使用场景有哪些?原理?内存泄漏?
ThreadLocal,即线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。
ThreadLocal的应用场景
- 数据库连接池
- 会话管理中使用
ThreadLocal原理
- Thread对象中持有一个ThreadLocal.ThreadLocalMap的成员变量。
- ThreadLocalMap内部维护了Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
- 每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
ThreadLocal 内存泄露问题
先看看一下的TreadLocal的引用示意图
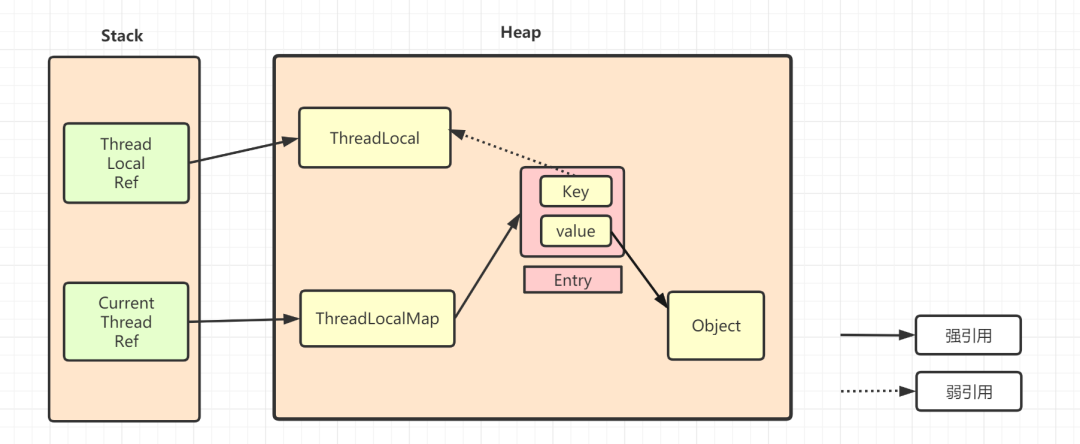
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用,如下
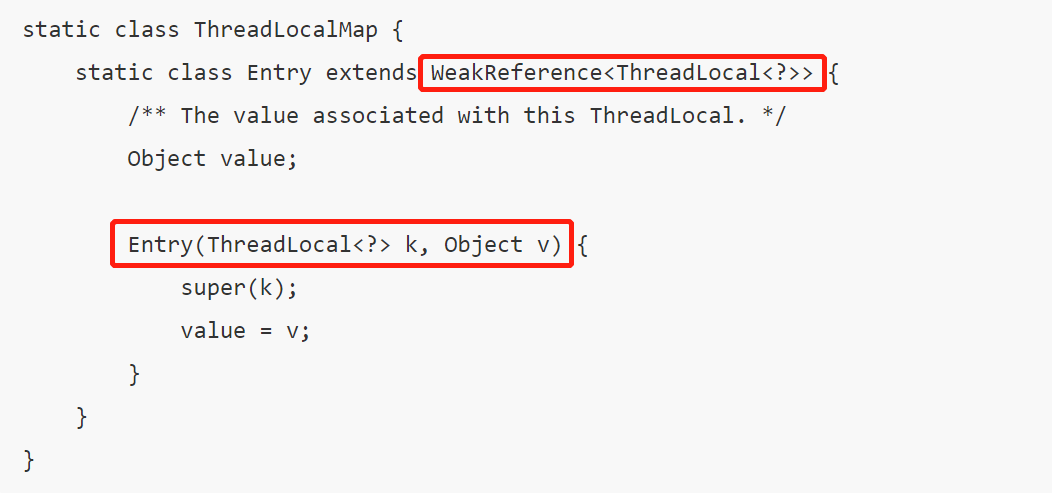
弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。
弱引用比较容易被回收。因此,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是因为ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
如何解决内存泄漏问题?使用完ThreadLocal后,及时调用remove()方法释放内存空间。
评论